
前面的前奏已经分析介绍了建立内核页表相关变量的设置准备,接下来转入正题分析内核页表的建立。
建立内核页表的关键函数init_mem_mapping():
【file:/arch/x86/mm/init.c】
void __init init_mem_mapping(void)
{
unsigned long end;
probe_page_size_mask();
#ifdef CONFIG_X86_64
end = max_pfn << PAGE_SHIFT;
#else
end = max_low_pfn << PAGE_SHIFT;
#endif
/* the ISA range is always mapped regardless of memory holes */
init_memory_mapping(0, ISA_END_ADDRESS);
/*
* If the allocation is in bottom-up direction, we setup direct mapping
* in bottom-up, otherwise we setup direct mapping in top-down.
*/
if (memblock_bottom_up()) {
unsigned long kernel_end = __pa_symbol(_end);
/*
* we need two separate calls here. This is because we want to
* allocate page tables above the kernel. So we first map
* [kernel_end, end) to make memory above the kernel be mapped
* as soon as possible. And then use page tables allocated above
* the kernel to map [ISA_END_ADDRESS, kernel_end).
*/
memory_map_bottom_up(kernel_end, end);
memory_map_bottom_up(ISA_END_ADDRESS, kernel_end);
} else {
memory_map_top_down(ISA_END_ADDRESS, end);
}
#ifdef CONFIG_X86_64
if (max_pfn > max_low_pfn) {
/* can we preseve max_low_pfn ?*/
max_low_pfn = max_pfn;
}
#else
early_ioremap_page_table_range_init();
#endif
load_cr3(swapper_pg_dir);
__flush_tlb_all();
early_memtest(0, max_pfn_mapped << PAGE_SHIFT);
}
其中probe_page_size_mask()实现:
【file:/arch/x86/mm/init.c】
static void __init probe_page_size_mask(void)
{
init_gbpages();
#if !defined(CONFIG_DEBUG_PAGEALLOC) && !defined(CONFIG_KMEMCHECK)
/*
* For CONFIG_DEBUG_PAGEALLOC, identity mapping will use small pages.
* This will simplify cpa(), which otherwise needs to support splitting
* large pages into small in interrupt context, etc.
*/
if (direct_gbpages)
page_size_mask |= 1 << PG_LEVEL_1G;
if (cpu_has_pse)
page_size_mask |= 1 << PG_LEVEL_2M;
#endif
/* Enable PSE if available */
if (cpu_has_pse)
set_in_cr4(X86_CR4_PSE);
/* Enable PGE if available */
if (cpu_has_pge) {
set_in_cr4(X86_CR4_PGE);
__supported_pte_mask |= _PAGE_GLOBAL;
}
}
probe_page_size_mask()主要作用是初始化直接映射变量(在init_gbpages()里面)和对page_size_mask变量进行设置,以及根据配置来控制CR4寄存器的置位,用于后面分页时的页面大小情况判定。
回到init_mem_mapping()继续往下走,接着是init_memory_mapping(),其中入参ISA_END_ADDRESS表示ISA总线上设备的地址末尾。
init_mem_mapping()实现:
【file:/arch/x86/mm/init.c】
/*
* Setup the direct mapping of the physical memory at PAGE_OFFSET.
* This runs before bootmem is initialized and gets pages directly from
* the physical memory. To access them they are temporarily mapped.
*/
unsigned long __init_refok init_memory_mapping(unsigned long start,
unsigned long end)
{
struct map_range mr[NR_RANGE_MR];
unsigned long ret = 0;
int nr_range, i;
pr_info("init_memory_mapping: [mem %#010lx-%#010lx]\n",
start, end - 1);
memset(mr, 0, sizeof(mr));
nr_range = split_mem_range(mr, 0, start, end);
for (i = 0; i < nr_range; i++)
ret = kernel_physical_mapping_init(mr[i].start, mr[i].end,
mr[i].page_size_mask);
add_pfn_range_mapped(start >> PAGE_SHIFT, ret >> PAGE_SHIFT);
return ret >> PAGE_SHIFT;
}
init_mem_mapping()里面关键操作有三个split_mem_range()、kernel_physical_mapping_init()和add_pfn_range_mapped()函数。
首先分析一下split_mem_range():
【file:/arch/x86/mm/init.c】
static int __meminit split_mem_range(struct map_range *mr, int nr_range,
unsigned long start,
unsigned long end)
{
unsigned long start_pfn, end_pfn, limit_pfn;
unsigned long pfn;
int i;
limit_pfn = PFN_DOWN(end);
/* head if not big page alignment ? */
pfn = start_pfn = PFN_DOWN(start);
#ifdef CONFIG_X86_32
/*
* Don't use a large page for the first 2/4MB of memory
* because there are often fixed size MTRRs in there
* and overlapping MTRRs into large pages can cause
* slowdowns.
*/
if (pfn == 0)
end_pfn = PFN_DOWN(PMD_SIZE);
else
end_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
#else /* CONFIG_X86_64 */
end_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
#endif
if (end_pfn > limit_pfn)
end_pfn = limit_pfn;
if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn, 0);
pfn = end_pfn;
}
/* big page (2M) range */
start_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
#ifdef CONFIG_X86_32
end_pfn = round_down(limit_pfn, PFN_DOWN(PMD_SIZE));
#else /* CONFIG_X86_64 */
end_pfn = round_up(pfn, PFN_DOWN(PUD_SIZE));
if (end_pfn > round_down(limit_pfn, PFN_DOWN(PMD_SIZE)))
end_pfn = round_down(limit_pfn, PFN_DOWN(PMD_SIZE));
#endif
if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn,
page_size_mask & (1<<PG_LEVEL_2M));
pfn = end_pfn;
}
#ifdef CONFIG_X86_64
/* big page (1G) range */
start_pfn = round_up(pfn, PFN_DOWN(PUD_SIZE));
end_pfn = round_down(limit_pfn, PFN_DOWN(PUD_SIZE));
if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn,
page_size_mask &
((1<<PG_LEVEL_2M)|(1<<PG_LEVEL_1G)));
pfn = end_pfn;
}
/* tail is not big page (1G) alignment */
start_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
end_pfn = round_down(limit_pfn, PFN_DOWN(PMD_SIZE));
if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn,
page_size_mask & (1<<PG_LEVEL_2M));
pfn = end_pfn;
}
#endif
/* tail is not big page (2M) alignment */
start_pfn = pfn;
end_pfn = limit_pfn;
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn, 0);
if (!after_bootmem)
adjust_range_page_size_mask(mr, nr_range);
/* try to merge same page size and continuous */
for (i = 0; nr_range > 1 && i < nr_range - 1; i++) {
unsigned long old_start;
if (mr[i].end != mr[i+1].start ||
mr[i].page_size_mask != mr[i+1].page_size_mask)
continue;
/* move it */
old_start = mr[i].start;
memmove(&mr[i], &mr[i+1],
(nr_range - 1 - i) * sizeof(struct map_range));
mr[i--].start = old_start;
nr_range--;
}
for (i = 0; i < nr_range; i++)
printk(KERN_DEBUG " [mem %#010lx-%#010lx] page %s\n",
mr[i].start, mr[i].end - 1,
(mr[i].page_size_mask & (1<<PG_LEVEL_1G))?"1G":(
(mr[i].page_size_mask & (1<<PG_LEVEL_2M))?"2M":"4k"));
return nr_range;
}
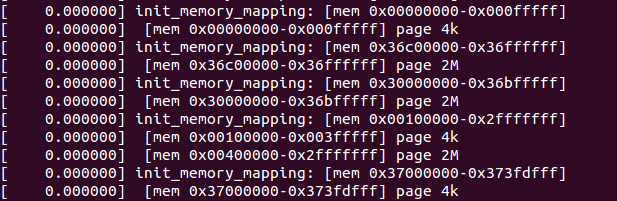
split_mem_range()根据传入的内存start和end做四舍五入的对齐操作(即round_up和round_down),并根据对齐的情况,把开始、末尾的不对齐部分及中间部分分成了三段,使用save_mr()将其存放在init_mem_mapping()的局部变量数组mr中。划分开来主要是为了允许各部分可以映射不同页面大小,然后如果各划分开来的部分是连续的,映射页面大小也是一致的,则将其合并。最后将映射的情况打印出来,在shell上使用dmesg命令可以看到该打印信息,样例:
接下来看kernel_physical_mapping_init():
【file:/arch/x86/mm/init.c】
/*
* This maps the physical memory to kernel virtual address space, a total
* of max_low_pfn pages, by creating page tables starting from address
* PAGE_OFFSET:
*/
unsigned long __init
kernel_physical_mapping_init(unsigned long start,
unsigned long end,
unsigned long page_size_mask)
{
int use_pse = page_size_mask == (1<<PG_LEVEL_2M);
unsigned long last_map_addr = end;
unsigned long start_pfn, end_pfn;
pgd_t *pgd_base = swapper_pg_dir;
int pgd_idx, pmd_idx, pte_ofs;
unsigned long pfn;
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte;
unsigned pages_2m, pages_4k;
int mapping_iter;
start_pfn = start >> PAGE_SHIFT;
end_pfn = end >> PAGE_SHIFT;
/*
* First iteration will setup identity mapping using large/small pages
* based on use_pse, with other attributes same as set by
* the early code in head_32.S
*
* Second iteration will setup the appropriate attributes (NX, GLOBAL..)
* as desired for the kernel identity mapping.
*
* This two pass mechanism conforms to the TLB app note which says:
*
* "Software should not write to a paging-structure entry in a way
* that would change, for any linear address, both the page size
* and either the page frame or attributes."
*/
mapping_iter = 1;
if (!cpu_has_pse)
use_pse = 0;
repeat:
pages_2m = pages_4k = 0;
pfn = start_pfn;
pgd_idx = pgd_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
pgd = pgd_base + pgd_idx;
for (; pgd_idx < PTRS_PER_PGD; pgd++, pgd_idx++) {
pmd = one_md_table_init(pgd);
if (pfn >= end_pfn)
continue;
#ifdef CONFIG_X86_PAE
pmd_idx = pmd_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
pmd += pmd_idx;
#else
pmd_idx = 0;
#endif
for (; pmd_idx < PTRS_PER_PMD && pfn < end_pfn;
pmd++, pmd_idx++) {
unsigned int addr = pfn * PAGE_SIZE + PAGE_OFFSET;
/*
* Map with big pages if possible, otherwise
* create normal page tables:
*/
if (use_pse) {
unsigned int addr2;
pgprot_t prot = PAGE_KERNEL_LARGE;
/*
* first pass will use the same initial
* identity mapping attribute + _PAGE_PSE.
*/
pgprot_t init_prot =
__pgprot(PTE_IDENT_ATTR |
_PAGE_PSE);
pfn &= PMD_MASK >> PAGE_SHIFT;
addr2 = (pfn + PTRS_PER_PTE-1) * PAGE_SIZE +
PAGE_OFFSET + PAGE_SIZE-1;
if (is_kernel_text(addr) ||
is_kernel_text(addr2))
prot = PAGE_KERNEL_LARGE_EXEC;
pages_2m++;
if (mapping_iter == 1)
set_pmd(pmd, pfn_pmd(pfn, init_prot));
else
set_pmd(pmd, pfn_pmd(pfn, prot));
pfn += PTRS_PER_PTE;
continue;
}
pte = one_page_table_init(pmd);
pte_ofs = pte_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
pte += pte_ofs;
for (; pte_ofs < PTRS_PER_PTE && pfn < end_pfn;
pte++, pfn++, pte_ofs++, addr += PAGE_SIZE) {
pgprot_t prot = PAGE_KERNEL;
/*
* first pass will use the same initial
* identity mapping attribute.
*/
pgprot_t init_prot = __pgprot(PTE_IDENT_ATTR);
if (is_kernel_text(addr))
prot = PAGE_KERNEL_EXEC;
pages_4k++;
if (mapping_iter == 1) {
set_pte(pte, pfn_pte(pfn, init_prot));
last_map_addr = (pfn << PAGE_SHIFT) + PAGE_SIZE;
} else
set_pte(pte, pfn_pte(pfn, prot));
}
}
}
if (mapping_iter == 1) {
/*
* update direct mapping page count only in the first
* iteration.
*/
update_page_count(PG_LEVEL_2M, pages_2m);
update_page_count(PG_LEVEL_4K, pages_4k);
/*
* local global flush tlb, which will flush the previous
* mappings present in both small and large page TLB's.
*/
__flush_tlb_all();
/*
* Second iteration will set the actual desired PTE attributes.
*/
mapping_iter = 2;
goto repeat;
}
return last_map_addr;
}
kernel_physical_mapping_init()是建立内核页表的一个关键函数,就是它负责处理物理内存的映射。swapper_pg_dir(来自于/arch/x86/kernel/head_32.s)就是页全局目录的空间了。而页表目录的空间则来自于调用one_page_table_init()申请而得,而one_page_table_init()则是通过调用关系:one_page_table_init()->alloc_low_page()->alloc_low_pages()->memblock_reserve()最后申请而得,同时页全局目录项的熟悉也在这里设置完毕,详细代码这里就不分析了。回到kernel_physical_mapping_init()代码中,该函数里面有个标签repeat,通过mapping_iter结合goto语句的控制,该标签下的代码将会执行两次。第一次执行时,内存映射设置如同head_32.s里面的一样,将页面属性设置为PTE_IDENT_ATTR;第二次执行时,会根据内核的情况设置具体的页面属性,默认是设置为PAGE_KERNEL,但如果经过is_kernel_text判断为内核代码空间,则设置为PAGE_KERNEL_EXEC。最终建立内核页表的同时,完成内存映射。
继续init_memory_mapping()的最后一个关键调用函数add_pfn_range_mapped():
【file:/arch/x86/mm/init.c】
struct range pfn_mapped[E820_X_MAX];
int nr_pfn_mapped;
static void add_pfn_range_mapped(unsigned long start_pfn, unsigned long end_pfn)
{
nr_pfn_mapped = add_range_with_merge(pfn_mapped, E820_X_MAX,
nr_pfn_mapped, start_pfn, end_pfn);
nr_pfn_mapped = clean_sort_range(pfn_mapped, E820_X_MAX);
max_pfn_mapped = max(max_pfn_mapped, end_pfn);
if (start_pfn < (1UL<<(32-PAGE_SHIFT)))
max_low_pfn_mapped = max(max_low_pfn_mapped,
min(end_pfn, 1UL<<(32-PAGE_SHIFT)));
}
该函数主要是将新增内存映射的物理页框范围加入到全局数组pfn_mapped中,其中nr_pfn_mapped用于表示数组中的有效项数量。由此一来,则可以通过内核函数pfn_range_is_mapped来判断指定的物理内存是否被映射,避免了重复映射的情况。
回到init_mem_mapping()继续往下,此时memblock_bottom_up()返回的memblock.bottom_up值仍为false,所以接着走的是else分支,调用memory_map_top_down(),入参为ISA_END_ADDRESS和end。其中end则是通过max_low_pfn << PAGE_SHIFT被设置为内核直接映射的最后页框所对应的地址。
memory_map_top_down()代码实现:
【file:/arch/x86/mm/init.c】
/**
* memory_map_top_down - Map [map_start, map_end) top down
* @map_start: start address of the target memory range
* @map_end: end address of the target memory range
*
* This function will setup direct mapping for memory range
* [map_start, map_end) in top-down. That said, the page tables
* will be allocated at the end of the memory, and we map the
* memory in top-down.
*/
static void __init memory_map_top_down(unsigned long map_start,
unsigned long map_end)
{
unsigned long real_end, start, last_start;
unsigned long step_size;
unsigned long addr;
unsigned long mapped_ram_size = 0;
unsigned long new_mapped_ram_size;
/* xen has big range in reserved near end of ram, skip it at first.*/
addr = memblock_find_in_range(map_start, map_end, PMD_SIZE, PMD_SIZE);
real_end = addr + PMD_SIZE;
/* step_size need to be small so pgt_buf from BRK could cover it */
step_size = PMD_SIZE;
max_pfn_mapped = 0; /* will get exact value next */
min_pfn_mapped = real_end >> PAGE_SHIFT;
last_start = start = real_end;
/*
* We start from the top (end of memory) and go to the bottom.
* The memblock_find_in_range() gets us a block of RAM from the
* end of RAM in [min_pfn_mapped, max_pfn_mapped) used as new pages
* for page table.
*/
while (last_start > map_start) {
if (last_start > step_size) {
start = round_down(last_start - 1, step_size);
if (start < map_start)
start = map_start;
} else
start = map_start;
new_mapped_ram_size = init_range_memory_mapping(start,
last_start);
last_start = start;
min_pfn_mapped = last_start >> PAGE_SHIFT;
/* only increase step_size after big range get mapped */
if (new_mapped_ram_size > mapped_ram_size)
step_size = get_new_step_size(step_size);
mapped_ram_size += new_mapped_ram_size;
}
if (real_end < map_end)
init_range_memory_mapping(real_end, map_end);
}
memory_map_top_down()首先使用memblock_find_in_range尝试查找内存,PMD_SIZE大小的内存(4M),确认建立页表的空间足够,然后开始建立页表,其关键函数是init_range_memory_mapping(),该函数的实现:
【file:/arch/x86/mm/init.c】
/*
* We need to iterate through the E820 memory map and create direct mappings
* for only E820_RAM and E820_KERN_RESERVED regions. We cannot simply
* create direct mappings for all pfns from [0 to max_low_pfn) and
* [4GB to max_pfn) because of possible memory holes in high addresses
* that cannot be marked as UC by fixed/variable range MTRRs.
* Depending on the alignment of E820 ranges, this may possibly result
* in using smaller size (i.e. 4K instead of 2M or 1G) page tables.
*
* init_mem_mapping() calls init_range_memory_mapping() with big range.
* That range would have hole in the middle or ends, and only ram parts
* will be mapped in init_range_memory_mapping().
*/
static unsigned long __init init_range_memory_mapping(
unsigned long r_start,
unsigned long r_end)
{
unsigned long start_pfn, end_pfn;
unsigned long mapped_ram_size = 0;
int i;
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, NULL) {
u64 start = clamp_val(PFN_PHYS(start_pfn), r_start, r_end);
u64 end = clamp_val(PFN_PHYS(end_pfn), r_start, r_end);
if (start >= end)
continue;
/*
* if it is overlapping with brk pgt, we need to
* alloc pgt buf from memblock instead.
*/
can_use_brk_pgt = max(start, (u64)pgt_buf_end<<PAGE_SHIFT) >=
min(end, (u64)pgt_buf_top<<PAGE_SHIFT);
init_memory_mapping(start, end);
mapped_ram_size += end - start;
can_use_brk_pgt = true;
}
return mapped_ram_size;
}
可以看到init_range_memory_mapping()调用了前面刚分析的init_memory_mapping()函数,由此可知,它将完成内核直接映射区(低端内存)的页表建立。此外可以注意到pgt_buf_end和pgt_buf_top的使用,在init_memory_mapping()函数调用前,变量can_use_brk_pgt的设置主要是为了避免内存空间重叠,仍然使用页表缓冲区空间。不过这只是64bit系统上才会出现的情况,而32bit系统上面则没有,因为32bit系统的kernel_physical_mapping_init()并不使用alloc_low_page()申请内存,所以不涉及。
至此,内核低端内存页表建立完毕。