
按:基于x86处理器上,以系统启动过程中内存管理的逐步构建为主轴,分析内存的管理方式与其相关的安全防护功能。

如何知道计算机内存布局?内存空间有多少?
春江水暖鸭先知,计算机上电启动的时候,BIOS会检测并计算物理内存大小。比方说现在通用的内存都是DIMM针脚插槽类型的,它的PIN针脚有两百多个,各个针脚各有自己的定义,BIOS就是通过对不同针脚的高低电平设置,由内存反馈其规格信息给BIOS,然后BIOS计算出容量。大概原理就这样了。但是我们重点是操作系统需要感知主机的内存空间,它是怎么知道的呢?它是通过BIOS提供的接口去询问出来的。这个接口就是0x15中断,其中参数重点参数是ax寄存器中需要设置值e820。然后通过intcall(0x15, &ireg, &oreg)中断调用,由BIOS通过oreg.di出参将内存信息返回回来。该实现在/arch/x86/boot/memory.c中的detect_memory,由于代码出参oreg.di也是ireg.di传进去的值,所以代码里面直接读了buf空间内存。由于每调用一次intcall只会返回一条内存数据信息,所以会循环调用多次才能够探明整个内存空间。
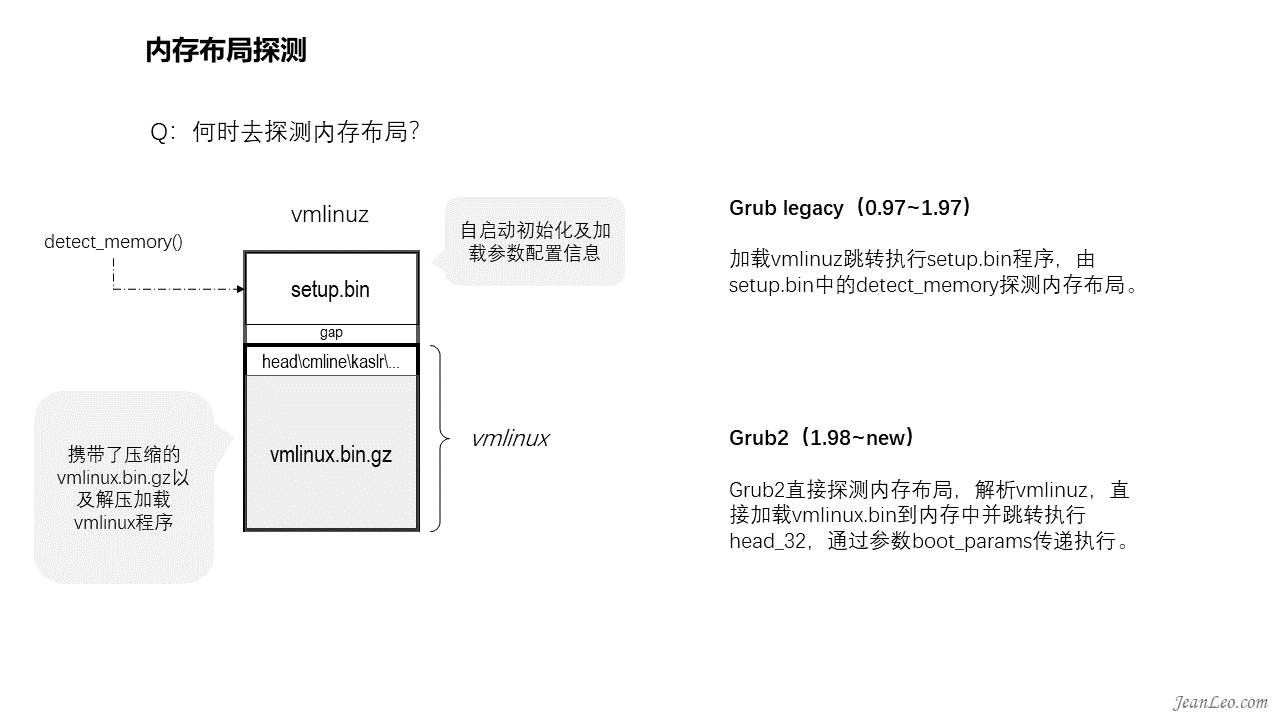
何时去探明内存布局?由谁去探明呢?
内存探测必然是kernel吗?答案是否定的。先说一下kernel的binary文件吧,它通常放在/boot/下面,名字通常命名为vmlinuz。这个文件是由setup.bin和vmlinux构造而成,其中vmlinux又由kernel编译目录arch/x86/boot/compressed下的cmdline.o、head.o、kaslr.o等连同压缩后的vmlinux.bin.gz合并构成。其中检测内存的detect_memory()函数就是在setup.bin里面,但是这仅限于Grub legacy(即Grup 0.97到1.97版本)引导kernel的时候,setup.bin才会被执行到,也就是仅在该情况下内存探测才是由kernel引导的领头羊去完成的。到了Grub2(即Grub 1.98到现在最新版本)引导linux系统的时候,则由Grub直接探明内存布局,然后解析vmlinuz文件,并且直接加载vmlinux部分的内容到内存中并跳转执行head_32函数,而内存布局则通过参数boot_params传递执行。谁探明内存布局对内存管理有影响吗?没影响的,所以这里是可以忽略的废话。既然废话就多说两句,为什么要分开setup.bin和vmlinux呢?这是因为setup.bin运行在实模式下面,而vmlinux则运行在保护模式下面。所以也就是说grub2是进入了保护模式后才加载引导的kernel。
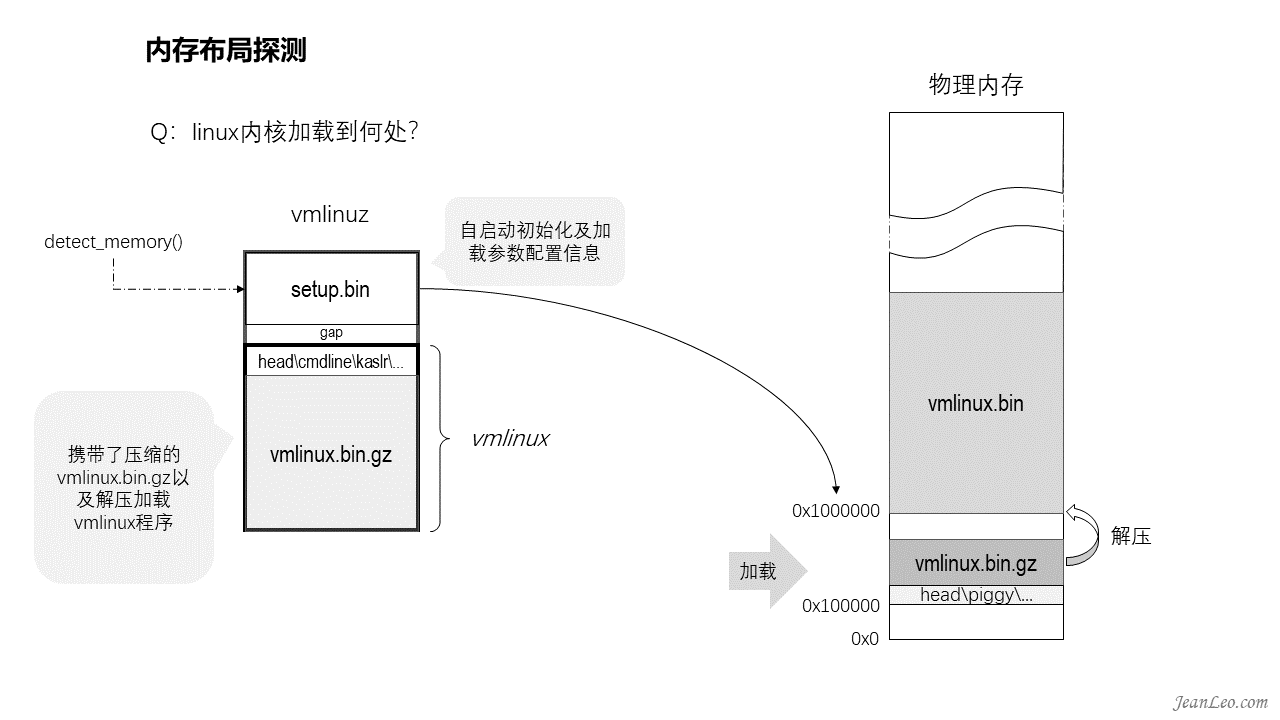
kernel会加载到何处呢?由什么决定它的位置?
setup.bin的首部512字节是一段MBR代码,它可以实现kernel自引导。紧挨着这512字节后面是kernel的加载信息,其中就包括了指示vmlinux的加载地址信息,通常是0x100000。它也不仅有vmlinux的加载地址信息,同时也携带了vmlinux.bin.gz解压的地址信息,通常为0x1000000。不过这都是建议值,可能会因一些状况加载到别处。比如接下来要讲的内核的自我防护。
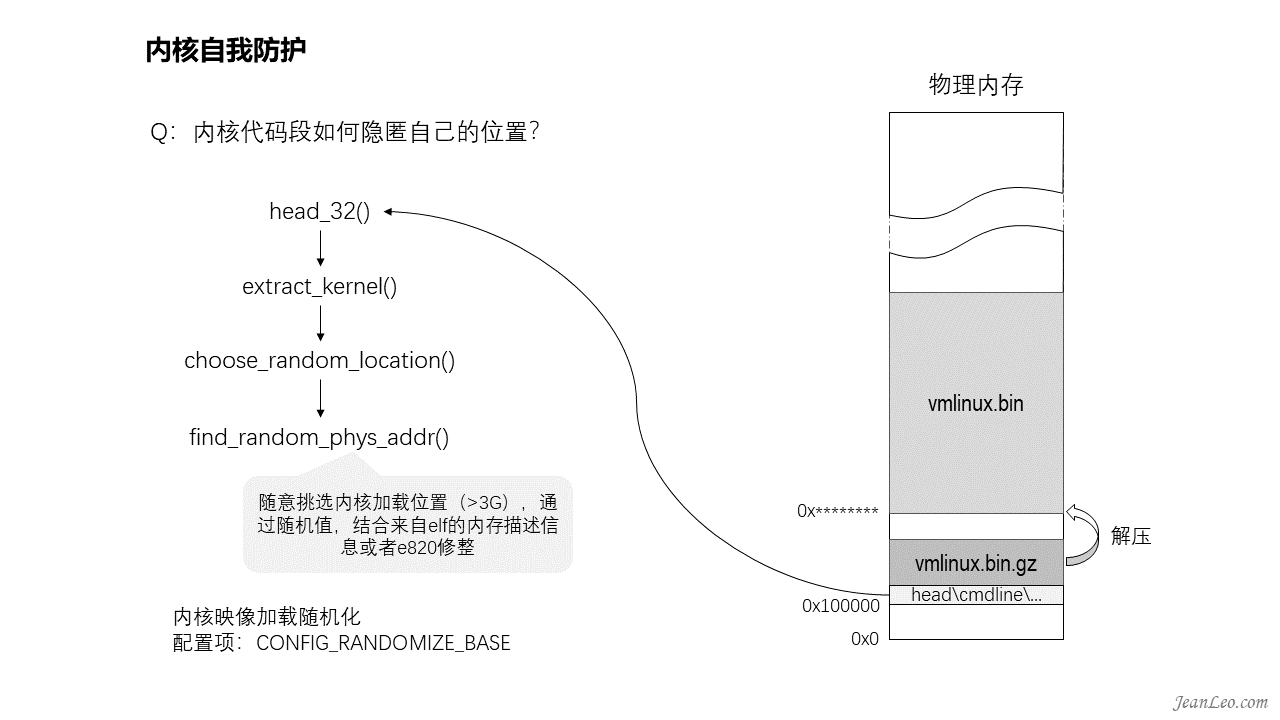
kernel映像如何隐匿自己的位置?
默认的情况下,kernel的映像是加载到了0x1000000的位置,由此攻击者分分钟可以通过地址偏移找到内核关键数据的位置,从而借助内核的越界、任意地址读写等漏洞发起攻击。因此kernel隐匿自己的位置可以很好地增加攻击者的难度,从而起到自我防护。所以引入了KASLR(kernel address space layout randomization),即内核地址空间布局随机化。该功能实现在arch/x86/boot/kaslr.c,由head_32()调用extract_kernel()执行kernel映像解压的时候,通过choose_random_location()调用find_random_phys_addr()使用随机值计算出加载位置。在32位环境下,它将随意挑选内核加载位置(>3G),通过随机值,结合来自elf的内存描述信息或者e820修整。该功能配置项为CONFIG_RANDOMIZE_BASE,也可以通过内核启动参数“nokaslr”进行关闭。
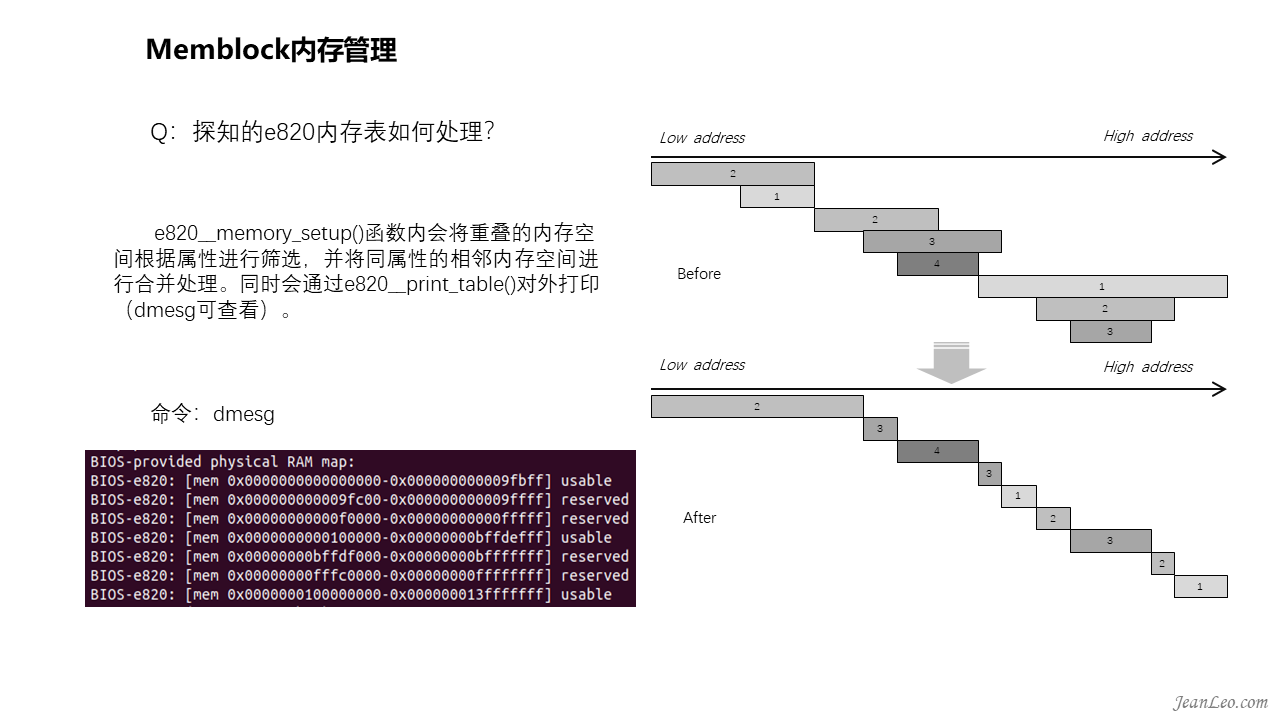
探知的e820表如何处理?
前面已经知道了如何探明内存空间得到e820图,得知了内存的位置、大小和类型。在e820__memory_setup()函数内会将重叠的内存空间根据属性进行筛选,并将同属性的相邻内存空间进行合并处理。整个处理过程如右侧所示,虽然实现上会对内存进行分割合并处理,但是实际上内存并不会这么错乱重叠的。处理完毕后,会通过e820__print_table()对外打印。通过dmesg可以看到如图左侧所示的信息。
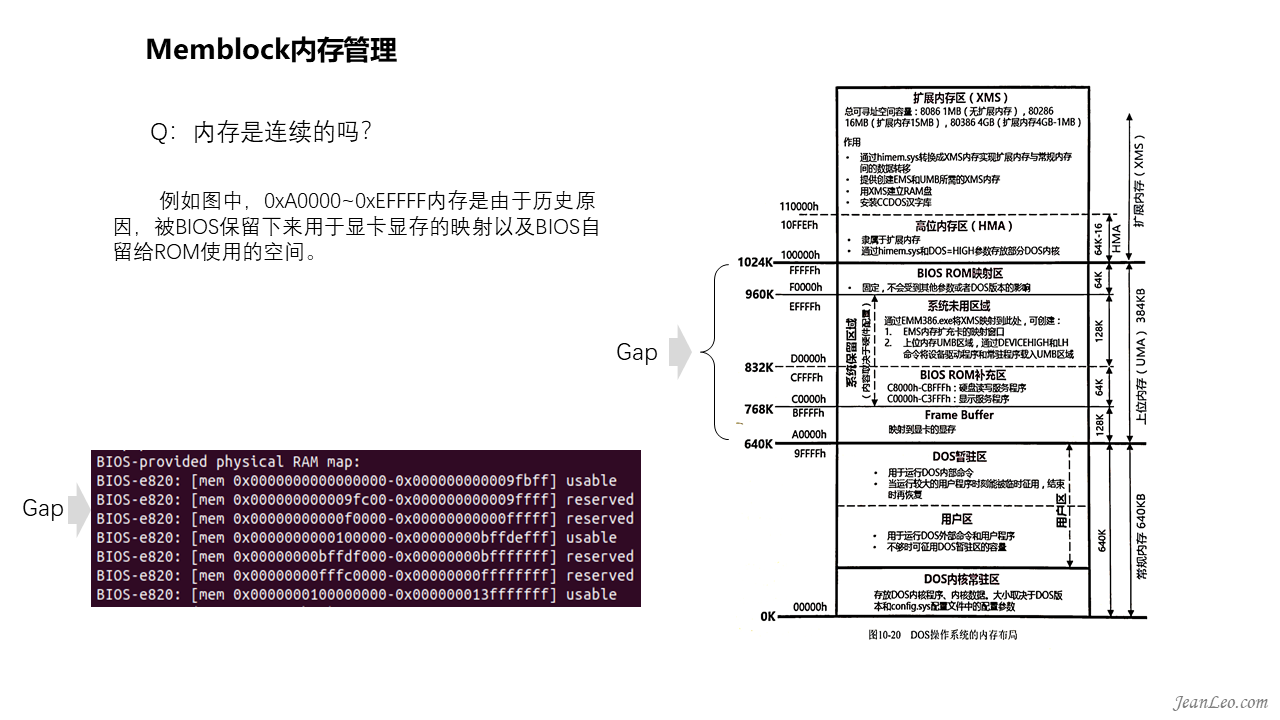
内存是连续的吗?
物理内存是连续的,但是细心的话,可以发现e820提供的数据中并不连续,中间0xA0000到0xFFFFF的内存并未在其中。这是历史原因遗留下来的,它并非不存在,而是被BIOS保留下来用作显卡显存的映射以及BIOS自留给ROM使用的空间。所以呈现出来有一个空洞位置。
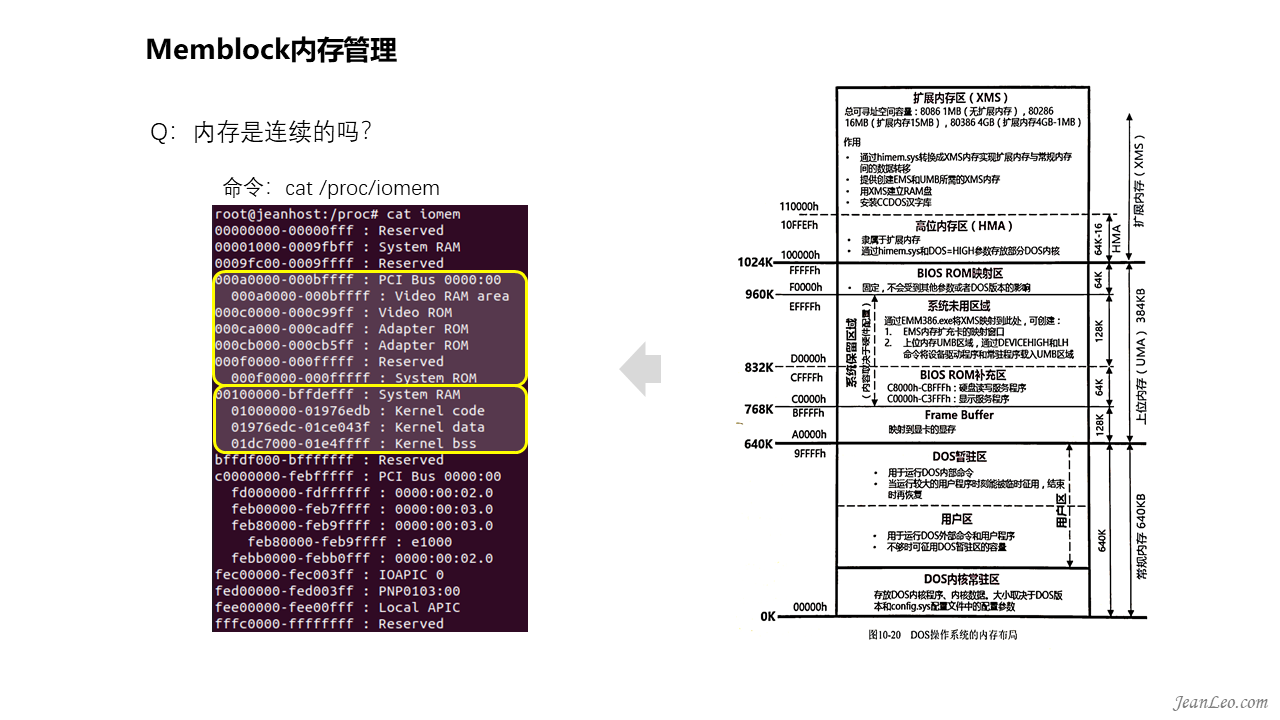
对此我们可以通过/proc/iomem查看到这些物理内存被如何划分分配。iomem主要呈现系统中设备的物理布局,包括未被e820所呈现的,它甚至能够将kernel在物理内存的加载位置呈现出来。
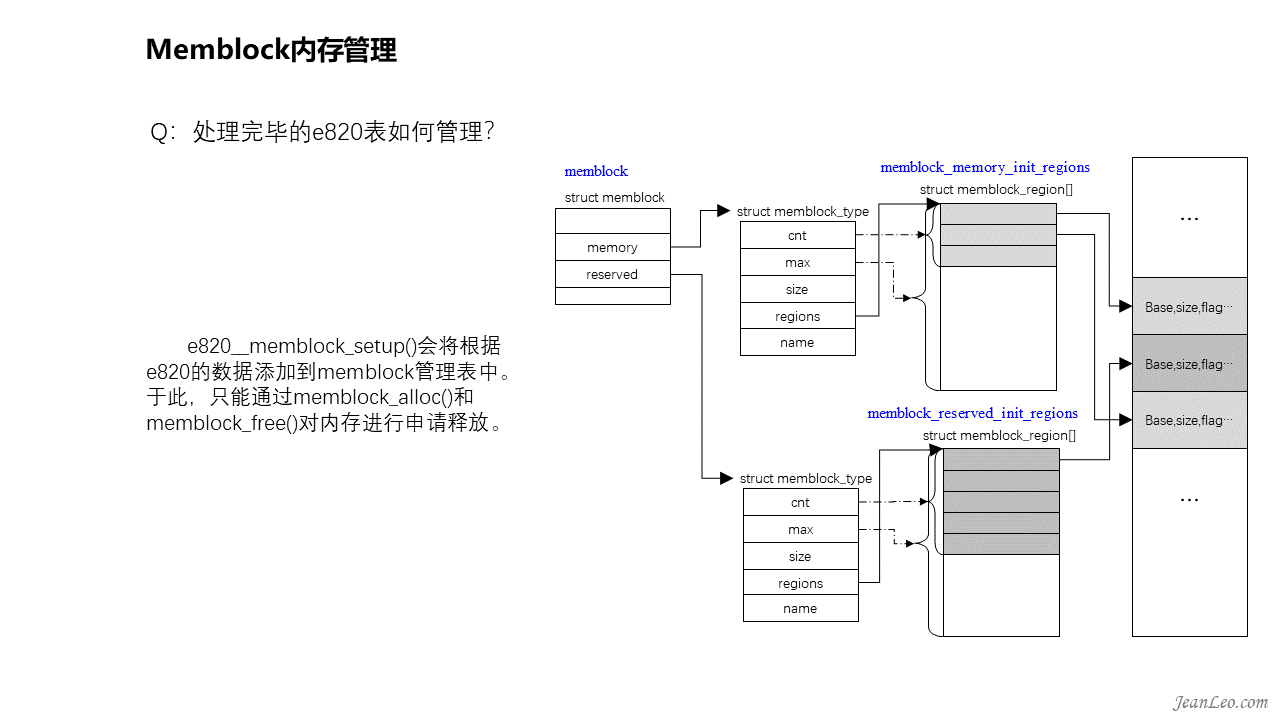
处理完毕的e820表如何管理?
经过按照类型的分割整合之后,e820__memblock_setup()会将根据e820的数据添加到memblock管理表中。memblock管理表由命名为memblock的全局数据结构变量管理,它主要通过可用内存memory和保留内存reserved两个成员结构体变量区分管理。例如可用内存全部都挂入到memblock.memory.regions下,该可用内存同时又以全局变量数组memblock_memory_init_regions而命名,该数组成员主要记录内存的基址、大小和类型,如图显示的是该算法的管理结构关系。类似的被保留的内存则在memblock_reserved_init_regions全局数组结构下管理。于此阶段,我们可以通过memblock_alloc()和memblock_free()对内存进行申请释放,而分配的方式很简单,根据需要分配的size到可用的内存空间memblock_memory_init_regions中去查找连续的等大小空间,然后将其分割开来,将分配出去的挂入到memblock_reserved_init_regions管理区中,而剩余的则放回到memblock_memory_init_regions。尤其是如果我们需要申请永久保留的内存可在此申请,即后续内存管理将不会对此内存进行分配回收管理。memblock内存管理只是一个过渡形态,不会长期存在,毕竟如此任意分割内存的分配方式长久运行后会导致严重的碎片化。因此后面将会建立内存映射,构造内存管理框架。

启动之时内存如何映射的?
CPU通电启动时默认进入实模式,这是源自于intel 8086的传承,向前兼容。于intel 8086的时候,内存地址总线为20bit,而寄存器为16bit,地址总线的宽度一般是要大于寄存器的宽度,所以为了能访问整个地址空间,需要采取特殊的寻址计算——分段寻址。物理地址由段地址(segment selector)与偏移量(offset)两部分组成,长度各是16bit。其中段地址左移4位(即乘以16)与偏移量相加即为物理地址。由于内存地址总线只有20bit,所以实际上只有1M内存空间可访问。但是如果base和offset都为0xffff的时候,可以访问最大的地址值为0x10FFEF ,由于仅能够访问到1M的内存空间,所以从0x100000到0x10ffef的内存空间实际上是0x0到0xffef,通过“wrapping”绕回回去了。而后演进到intel 80286,可以通过A20关闭绕回。但是打开A20 Gate后,只是在实模式上使得处理器能够最大化访问0x10ffef的地址空间,而不是wrap绕回去访问低地址空间。但是要想访问0x10ffef以上的内存,则必须进入保护模式。
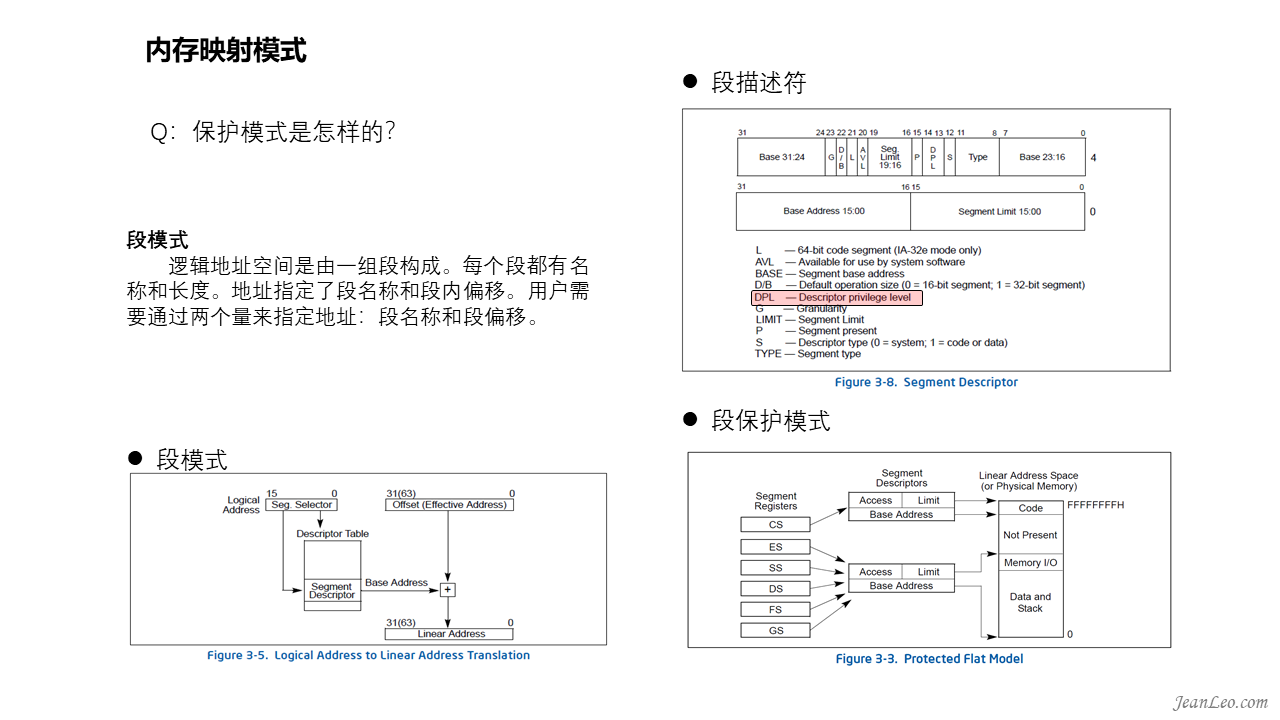
保护模式是怎样的?相比实模式有何特点?
了解过linux内存的都知道有页保护模式,但是实际上对于x86而言,段模式已经是保护模式了。段模式是怎样的呢?它的逻辑地址空间是由一组段构成。每个段都有名称和长度。地址指定了段名称和段内偏移。用户需要通过两个量来指定地址:段名称和段偏移。如何启动保护作用呢?寻址时根据不同的段寄存器内容查找到对应的段描述符,描述符指明了此时的环境的可以通过段访问到内存基地址、空间大小和访问权限。访问权限则点明了哪些内存可读、哪些内存可写。如图中DPL描述本段内存所需权限。所以段模式就是保护模式了。不过实际上,linux并不使用段保护功能。这里只是略提一下。
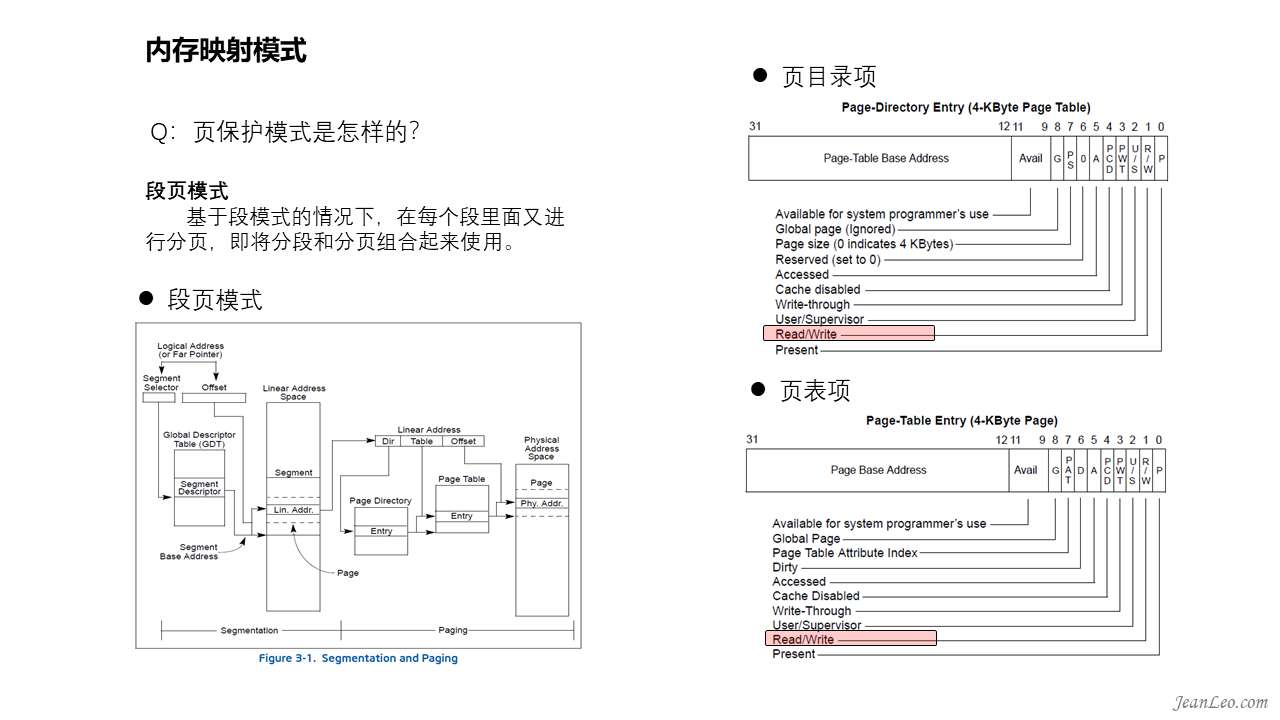
页保护模式是怎样的?
X86的页保护模式就是段页模式,基于段模式的情况下,在每个段里面又进行分级分页,形成将分段和分页组合起来使用的情况,可以参考上图。x86是无法绕过段模式,而独立开启使用页模式的。分析Linux最初进入保护模式的实现,可以看到linux开启段模式仅是一种纯段式的内存映射模式,并不会开启段的保护模式。因为Linux是不使用段保护的,使用的是页保护,所以Linux在后面还会构建页表建立页映射并开启分页管理。linux对段模式的处理就是每个段都是0~4G的地址空间,相当于什么也没有做一样,剩下的管理全由分页机制来实现。同时在分页的过程中,页目录项和页表项里面的字段都保留了R/W位用来保护是否可写。篇外话,如果对CPU比较熟悉的话,可以留意到x86这种经典分页模式并没有提供执行权限位的设置,也因此经典的x86分页是允许程序在栈上执行代码的原因,由此很容易利用栈缓冲区溢出。
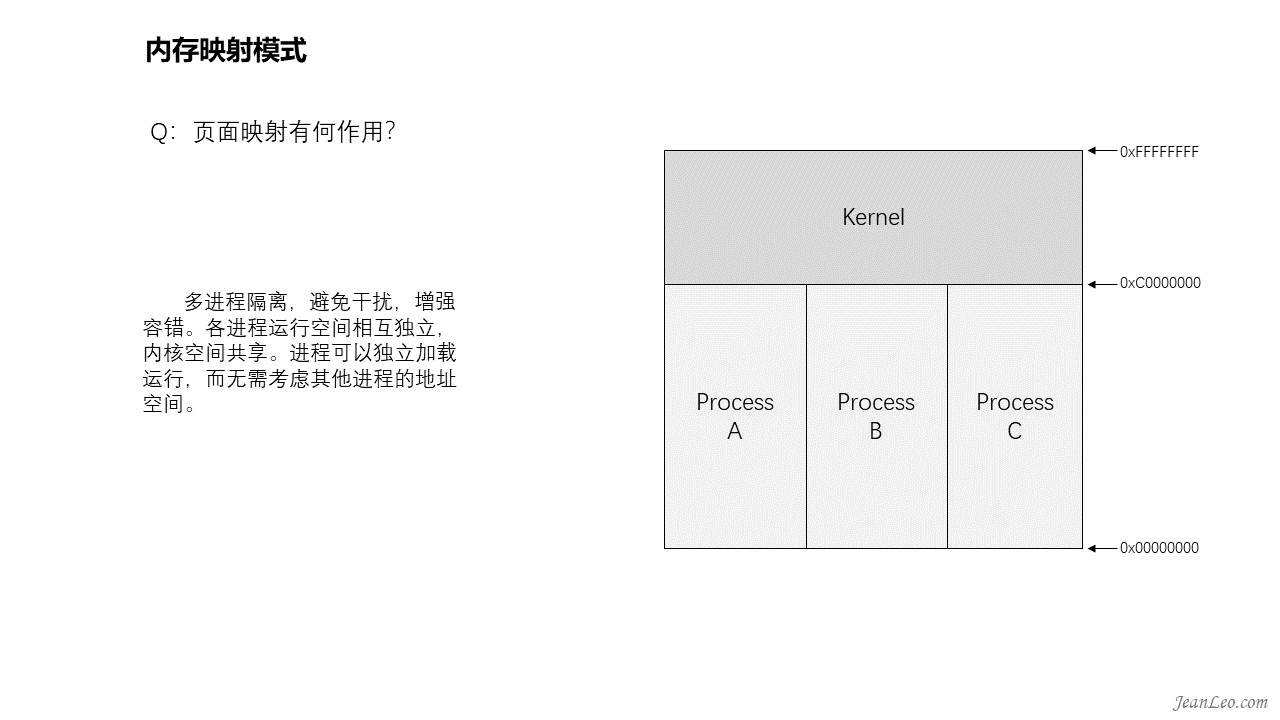
页面映射有何作用?都有什么好处?
页面映射,根据处理器的不同,可以划分为不同大小的页面,相比段模式,粒度更小,从而降低了物理内存的内部碎片化。同时页目录、页表等如同桥梁一般,将物理内存和虚拟内存关联起来。可以实现多进程隔离,每个进程都有自己独立的地址空间,进程可以独立加载运行,而无需考虑对其他进程的地址空间的影响。避免相互干扰,增强容错。此外也更易于实现内存共享,如同内核空间就是多进程共享。更重要的是提升了安全性,对所有进程暴露的仅有虚拟内存空间,而物理地址空间则被隐匿起来。
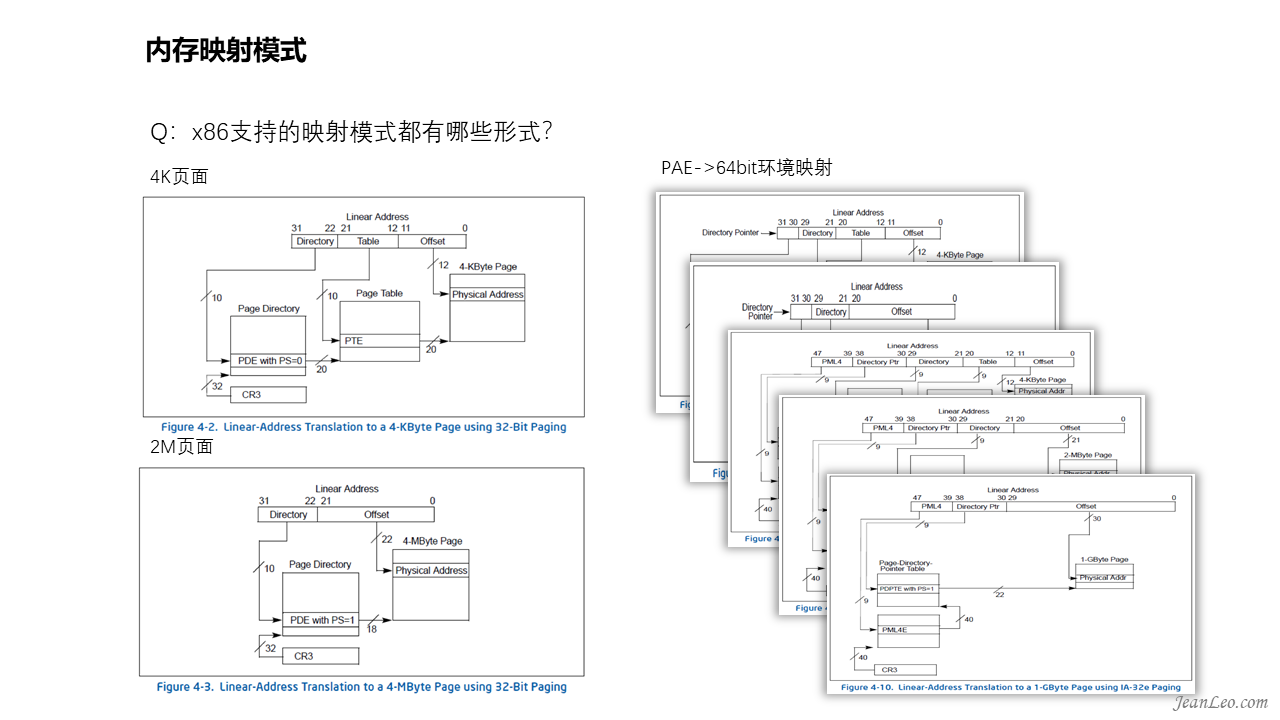
x86支持的映射模式都有哪些形式?如何分级的?
内存页面的分级映射取决于所需映射的内存页面大小。为什么需要有不同的大小页面呢?因为过小的页面大小会带来较大的页表项增加寻址时 TLB(Translation lookaside buffer)的查找速度和额外开销;过大的页面大小会浪费内存空间,造成内存碎片,降低内存的利用率。例如32位环境,其支持4k大小页面,同时也支持2M的大页面。如图所示,4k页面需要2级映射关系,而2M页面仅需1级映射关系。而PAE(Physical Address Extension),即物理地址扩展实体位置延伸,是x86处理器的一个功能,让中央处理器在32位操作系统下访问超过4GB的物理内存,在4k页面映射下就已经需要3级映射关系了。而到了64位,则从4k页面到2M页面,甚至支持1G页面的映射,进而演进到4k需要4级映射。
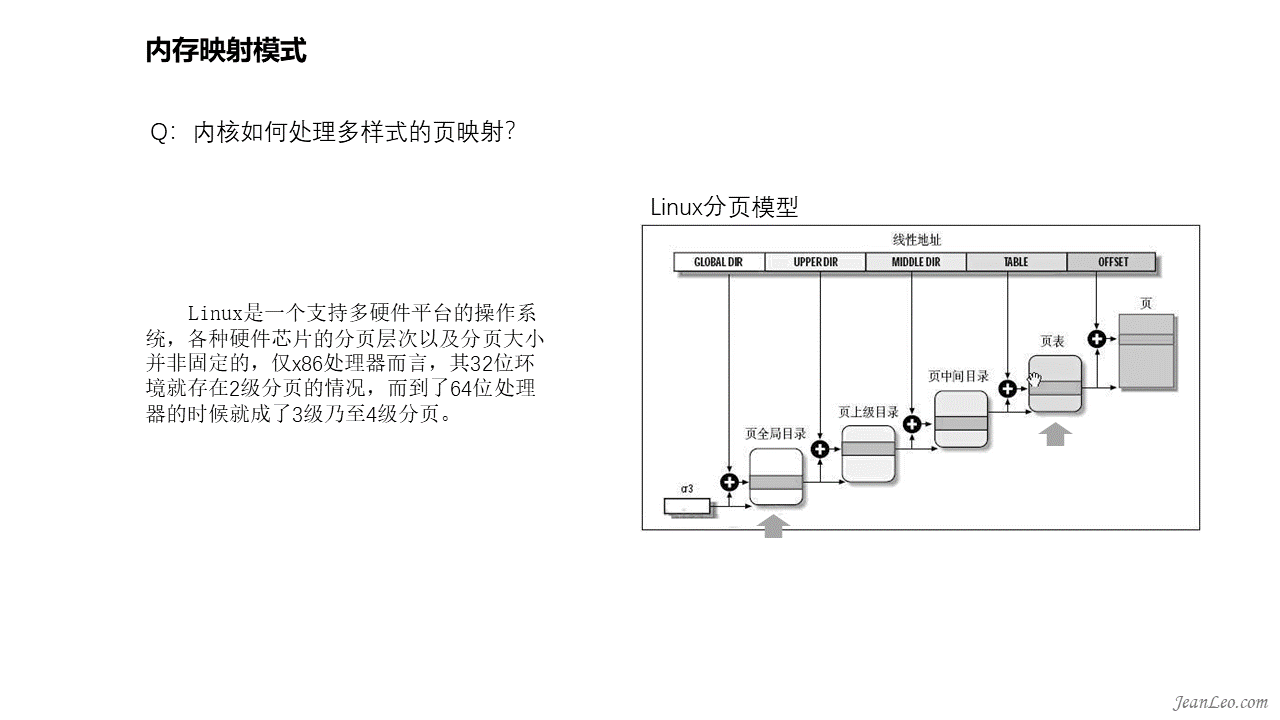
内核如何处理多样式的页映射?
Linux是一个支持多硬件平台的操作系统,各种硬件芯片的分页层次以及分页大小并非固定的,仅x86处理器而言,其32位环境就存在2级分页的情况,而到了64位处理器的时候就成了最多4级分页。对此Linux采取了以不变应万变的形势,划分了页全局目录、页上级目录、页中间目录、页表等,然后按需设置。例如x86的32位环境映射4k页面,则页上级目录和页中间目录的bit位设置为0,访问和设置时均空操作返回,仅余页全局目录和页表的存在,对其设置相应的bit位长度,实现相应的设置功能,即可使基于分页模式上的上层应用无差异化运行。
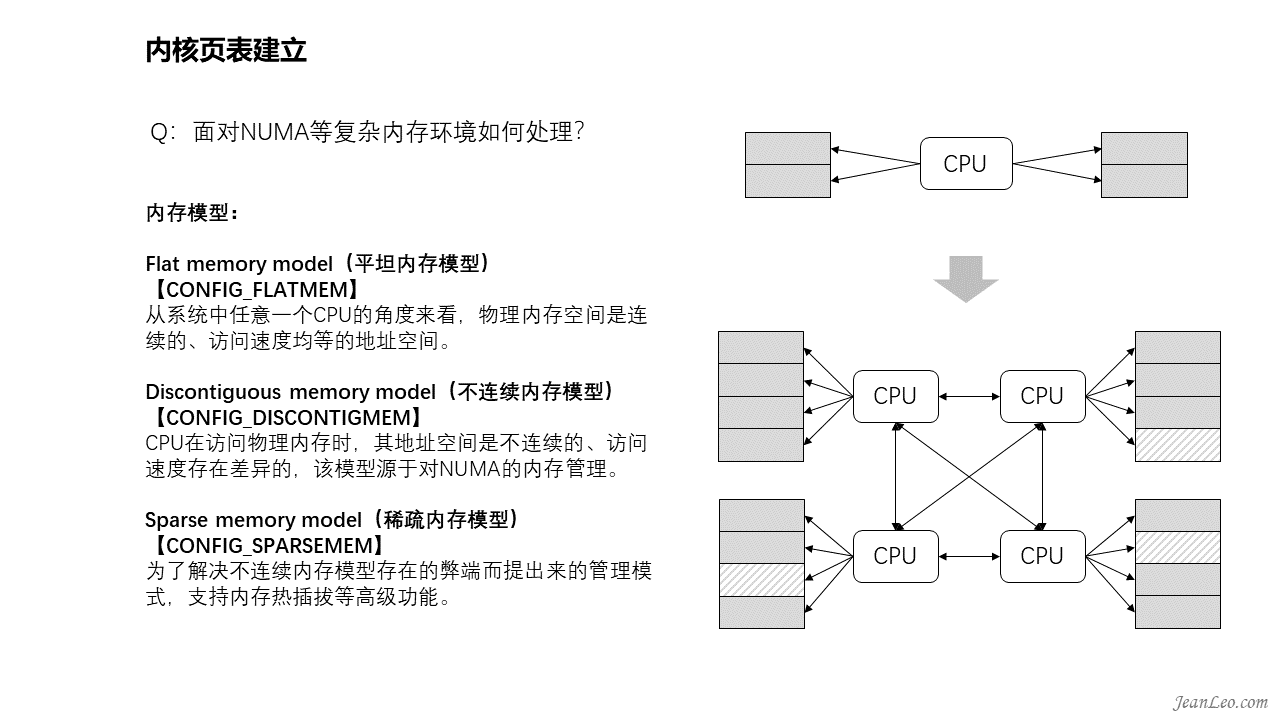
面对NUMA等复杂内存环境如何处理?
这里主要讲一下内存模型,所谓内存模型,其实就是从cpu的角度看,其物理内存的分布情况,在linux kernel中,使用什么的方式来管理这些物理内存。主要有三种内存模型:flat memory model,Discontiguous memory model和sparse memory model。其中平坦内存模型(Flat memory model)主要特点是CPU访问系统的整个内存,其物理内存空间是连续的,并且访问任意点的时间和速度都是相同的。而管理上,每一个物理页帧都会有一个page数据结构来抽象,因此系统中存在一个struct page的数组(mem_map),每一个数组条目指向一个实际的物理页帧(page frame)。物理页面与page结构数组关系是一一对应。随着计算机发展,后面多CPU的出现,每个CPU都有自己独立的内存通道,通过自己的内存通道访问与之连接的内存,其速度是均匀的。但是如果要是想访问其他CPU内存通道连接的内存,则时间上开销就慢许多了,而且内存甚至不连续,由此造成了全局内存的访问速度差异以及不连续性。这就是NUMA架构的由来,为此引入了不连续内存模型(Discontiguous memory model)。该模型对内存的管理是平坦模型的延续,它将连续的访问速度一致的一片大内存归为一个node,而node内的内存管理则采用了平台内存模型的管理方式,page结构数组与物理页面一一对应管理。其中每个node管理的物理内存page结构保存在struct pglist_data 数据结构的node_mem_map成员中。但是技术永远在进步,随着hotplug内存热插拔的出现,那么node节点内的内存也可能出现不连续的情况,由此又演进出了稀疏内存管理模型(Sparse memory model),该模型下连续的地址空间按照SECTION(例如1G)被分成了一段一段的,其中每一section都是hotplug的。内存管理的时候,整个连续的物理地址空间是按照一个section一个section来切断的,每一个section内部,其memory是连续的(即符合flat memory的特点),因此,mem_map的page数组依附于section结构(struct mem_section)而不是node结构了(struct pglist_data)。实际上不连续内存模型和稀疏内存模型都可以对NUMA架构进行内存管理,因为NUMA没有明确内存必须连续的,所以两种模型都可以管理NUMA架构的内存。
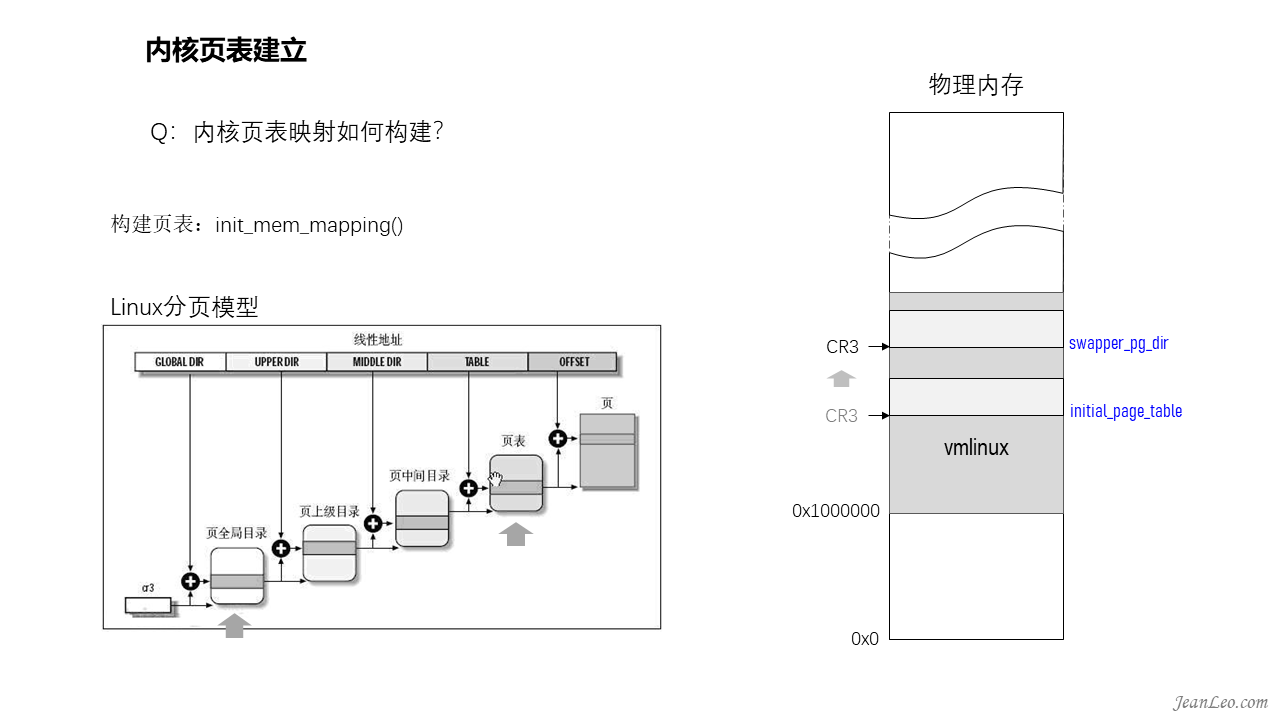
内核页表如何建立?
进入start_kernel前,是通过initial_page_table构建的页全局目录,到了setup_arch的时候,会将其部分页目录信息拷贝到swapper_pg_dir里面,而页表则是通过memblock内存管理分配而来,最后在init_mem_mapping通过init_memory_mapping把所有内存映射起来,包括0到0x100000的ISA内存以及它的空洞部分(即驱动及ROM保留的部分)。建立内存映射需要多少内存呢?以32位系统为例,4G空间除以4k页面大小(offset的12bit代表的空间)得到页表项数,再乘以每项页表4byte的大小,可以得到如果映射完了,需要4M大小的页表空间。而页全局目录经过同样的换算,可以得知仅需4k内存,一个内存页而已。
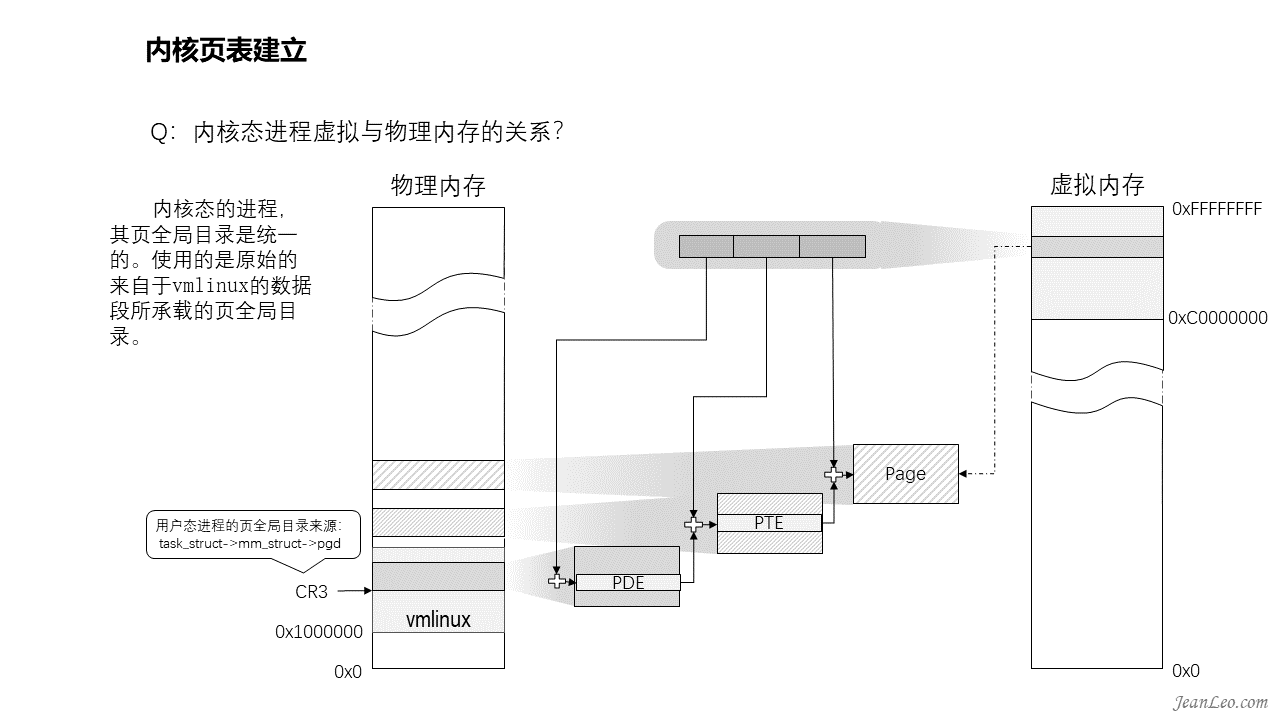
内核态进程虚拟地址与物理内存的映射关系?
内核态的进程,其页全局目录基本是统一的。虽然各个进程都有自己的管理结构task_struct,该结构内mm_struct结构成员pgd记录着其页全局目录,但是只要它没有过多的内存诉求的情况下,是不会触发内存分配修改页全局目录的操作,因此使用的是原始的来自于vmlinux的数据段所承载的页全局目录,即swapper_pg_dir指向的位置。那么页表PTE也则是复用页表映射时memblock分配的内存。如果涉及到驱动相关的内核进程,它们需要对设备接口做内存映射,这时候就会触发写时拷贝动作,分配新的内存作为页全局目录,将所有表项拷贝过去,然后基于此进行修改。
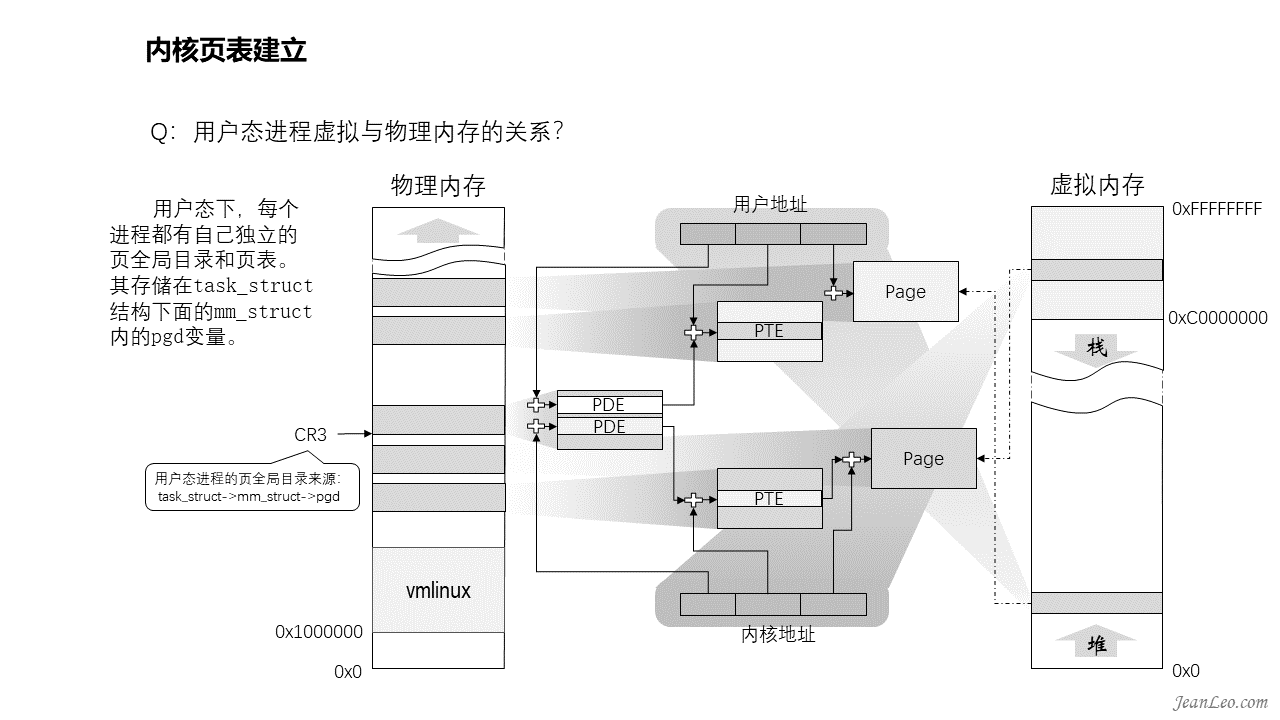
用户态进程虚拟内存与物理内存的关系如何?
纯内核态进程是不需要访问0到3G的内存空间的,因此其页表映射不需要这部分的映射关系。但是用户态进程则是需要的,因此它的页全局目录会有更多的页表映射,除了内核空间的页表映射项可以复用以外,也需要更多映射到用户空间的页表,所以用户态下每个进程都有自己独立的页全局目录和部分私有的页表。同样其页全局目录存储在task_struct结构下面的mm_struct内的pgd变量。
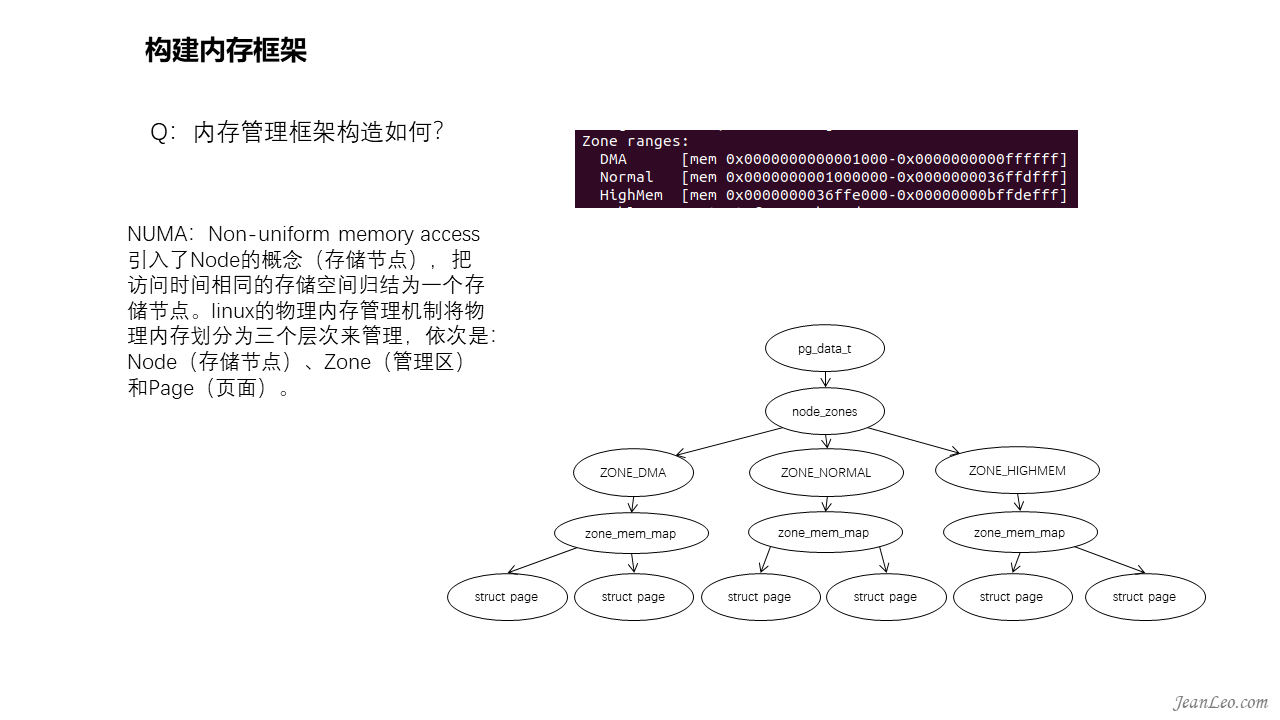
内存管理框架如何构造?
NUMA:Non-uniform memory access,即非一致性内存访问。它引入了node的概念(存储节点),把访问时间相同的存储空间归结为一个node节点。对于多CPU的复杂环境则需要多个node节点数据(struct pglist_data)来管理,而通过宏定义NODE_DATA可以得到指定节点的struct pglist_data(即pg_data_t)。后面将会基于单个node的情形进行分析。基于node的struct pglist_data结构下则有着struct zone用来管理具体的物理内存页。zone的存在是由于32位环境下内存空间限制,内存分配的用途和速度上的差异而存在的,64位环境基本淡化了。其中ZONE_DMA(0-16MB)是某些ISA设备所需的低地址范围的物理内存,而ZONE_NORMAL(16MB-896MB)中的内存直接映射到线性地址空间的上部区域,高性能内存分配区域,至于ZONE_HIGHMEM (896MB以上)则是系统中剩余的可用内存,并不由内核直接映射,分配时还需要重新映射,性能略逊一筹。总而言之,linux的物理内存管理机制将物理内存划分为三个层次来管理,依次是:Node(存储节点)、Zone(管理区)和Page(页面)。此外,NUMA强调的是memory和CPU的位置关系,和内存模型其实是没有关系的。如果非要说关系的话,内存管理框架和内存模型的关系可以理解为:管理维度不同,内存管理模型类似于档案式管理,每页内存都有一个struct page的结构体档案,而内存模型类似于军队编制化管理,按照军团连方式层级划分管理,直接是内存页面。内存管理框架的构建主要是在initmem_init()函数内实现。
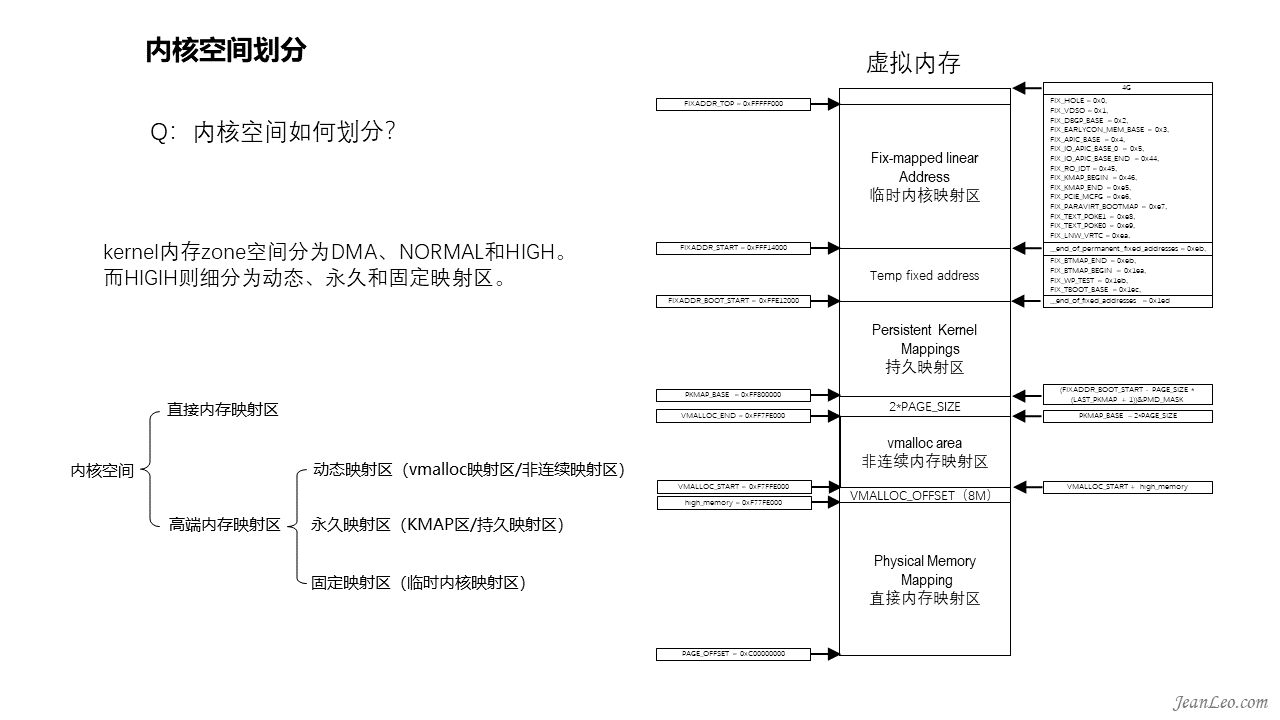
Kernel内存空间如何划分?
前面讲到了内存框架,kernel将zone分为了DMA、NORMAL和HIGH。从映射的角度而言,分为直接内存映射区和高端内存映射区。其中直接内存映射区是指3G到3G+896M的线性空间,直接对应物理地址就是0到896M(前提是有超过896M的物理内存),包括DMA和NORMAL两个zone,其中896M是high_memory值定义的大小,该区内存使用kmalloc()/kfree()接口操作申请释放;而高端内存映射区则是超过896M物理内存的空间,它又分为动态映射区、永久映射区和固定映射区。动态内存映射区,又称之为vmalloc映射区或非连续映射区,是指VMALLOC_START到VMALLOC_END的地址空间,申请释放操作接口是vmalloc()/vfree(),通常用于将非连续的物理内存映射为连续的线性地址内存空间;而永久映射区,又称之为KMAP区或持久映射区,是指自PKMAP_BASE开始共LAST_PKMAP个页面大小的空间,操作接口是kmap()/kunmap(),用于将高端内存长久映射到内存虚拟地址空间中;最后的固定映射区,也称之为临时内核映射区,是指FIXADDR_START到FIXADDR_TOP的地址空间,操作接口是kmap_atomic()/kummap_atomic(),用于解决持久映射不能用于中断处理程序而增加的临时内核映射。
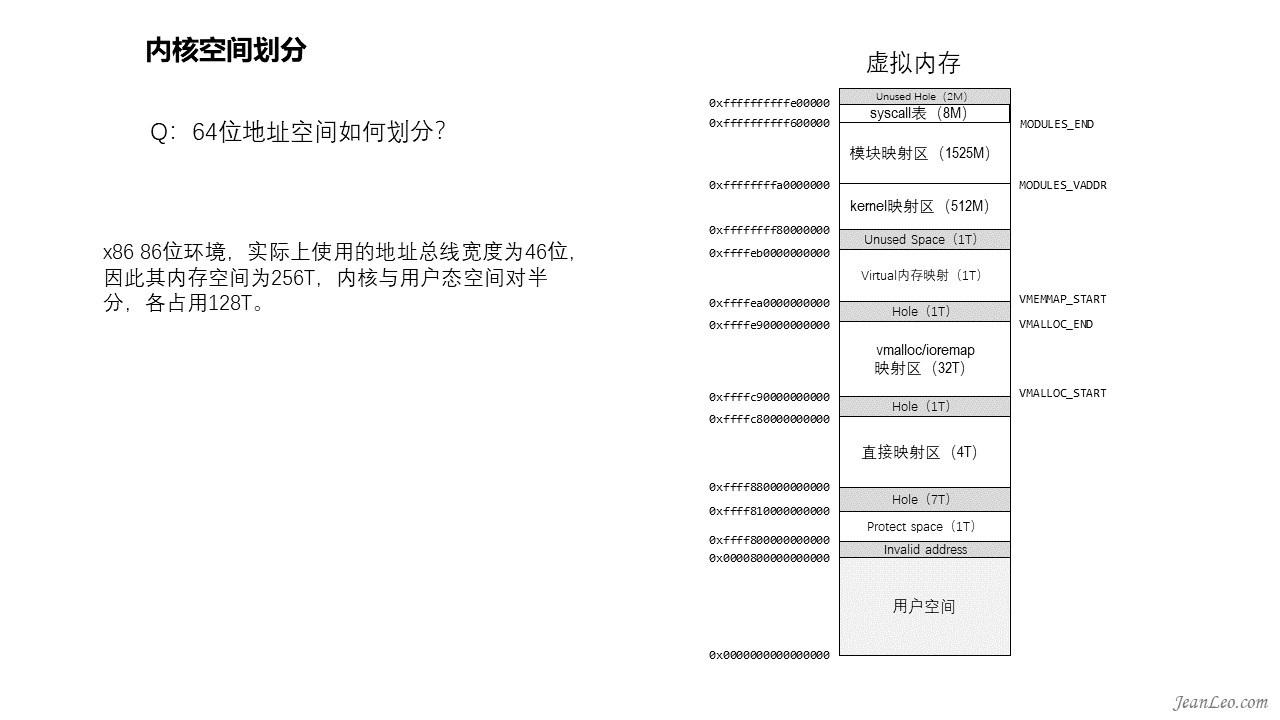
64位地址空间如何划分?
x86 86位环境,实际上使用的地址总线宽度为46位,因此其最大支持的内存空间为256T,相比32位环境,内存更加宽裕了,因此内核与用户态空间对半分,各占用128T。由于有了更广阔的空间,所以内存布局和32位相比,就有了很大的不同,但这也仅是布局上的不同而已,对于内存管理算法机制还是基本一致的。这里就不展开细讲其布局了。
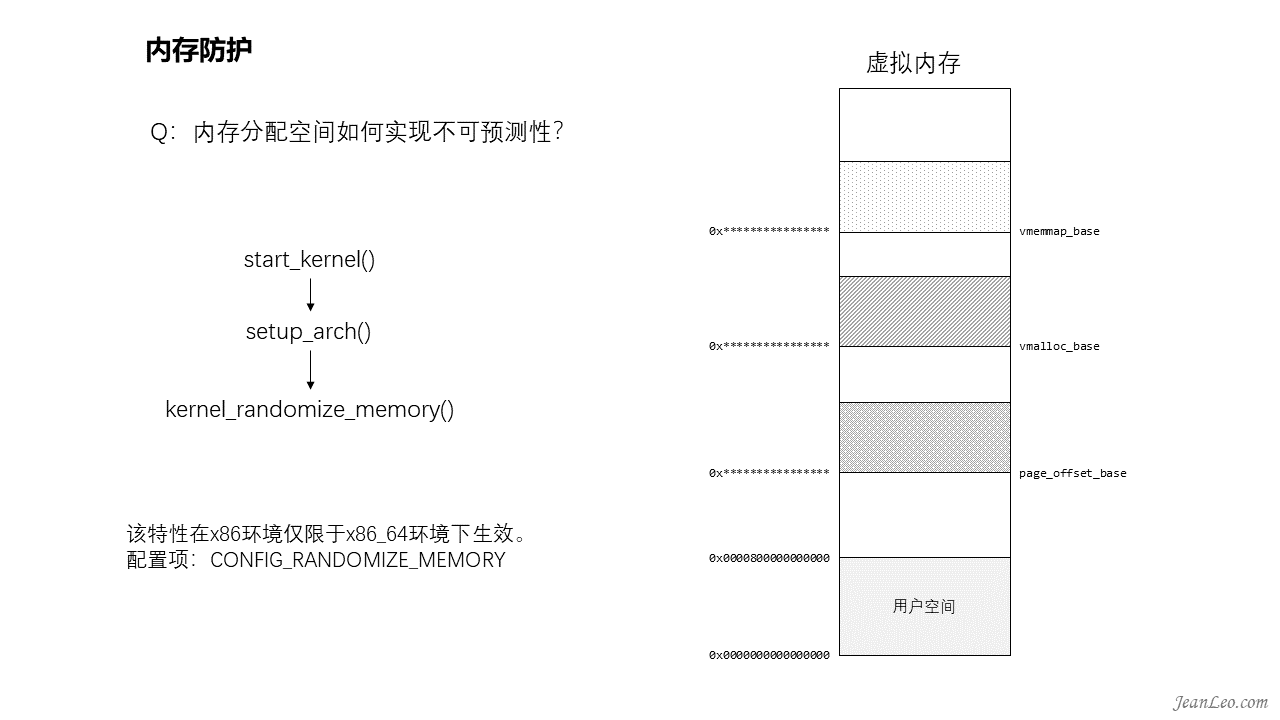
内存分配空间如何实现不可预测性?
内存分配空间的随机性是在setup_arch()中,通过kernel_randomize_memory()来实现的,主要是将直接映射区域基址(page_offset_base)、vmalloc区域基址(vmalloc_base)、vmemmap区域基址(vmemmap_base)这三个地址进行随机化。这三块内存的基址变了,将会使得分配内存的位置不可预判,在哪个范围都不确定,更何况位置。但是这功能仅能在地址空闲富裕的64位环境上通过CONFIG_RANDOMIZE_MEMORY配置项使能,32位环境则无该功能,毕竟地址空闲有限,不过前面提到的kaslr实际上也是会对32位的内存分配地址空间产生间接的影响。
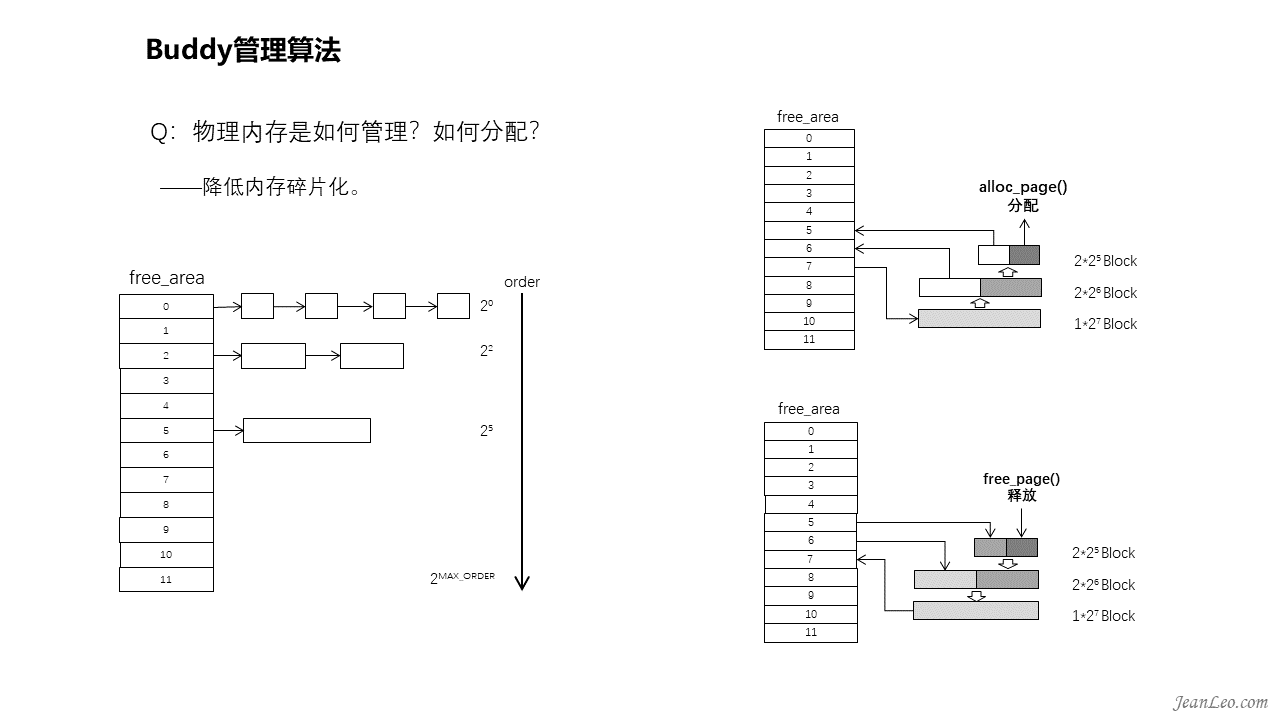
物理内存是如何管理的?怎么分配的?
通过前面已经知道了e820的内存交给了memblock管理,一个很粗犷的管理方式,存在着碎片化的风险。所以为了降低内存的外部碎片化,内存将会交给Buddy管理算法进行管理。该算法特点是基于MAX_ORDER为11的情况,构造一个倍增型哈希表,各个表项下的页面链表分别表示为:1、2、4、8、16、32、64、128、256、512、1024个连续的页面,即按照翻倍的形式来递进组织,而且每个页面块的第一个页面的物理地址是该块大小的整数倍。假设物理内存连续,各空闲页面块左右的页面,要么是等同大小,要么就是整数倍,而且还是偶数,形同伙伴。分配的时候,先从满足申请大小的链表中提取空闲页面块,如果链表为空,则会往高一阶的页面块链表进行查找,如果依旧没找到,则继续往高阶进行查找,直到找到为止,否则就是申请失败了。如果在高阶的页面块链表找到空闲的页面块,则会将其拆分为两块,如果拆分后仍比需要的大,那么继续拆分,直至到大小刚好为止。而释放则放入到对应大小的链表中,同时判断相邻等大小的内存页面块是否存在,若存在则将两者合并放入到高一阶链表中,依此类推。alloc_page()和free_page()则是物理内存的分配释放入口。
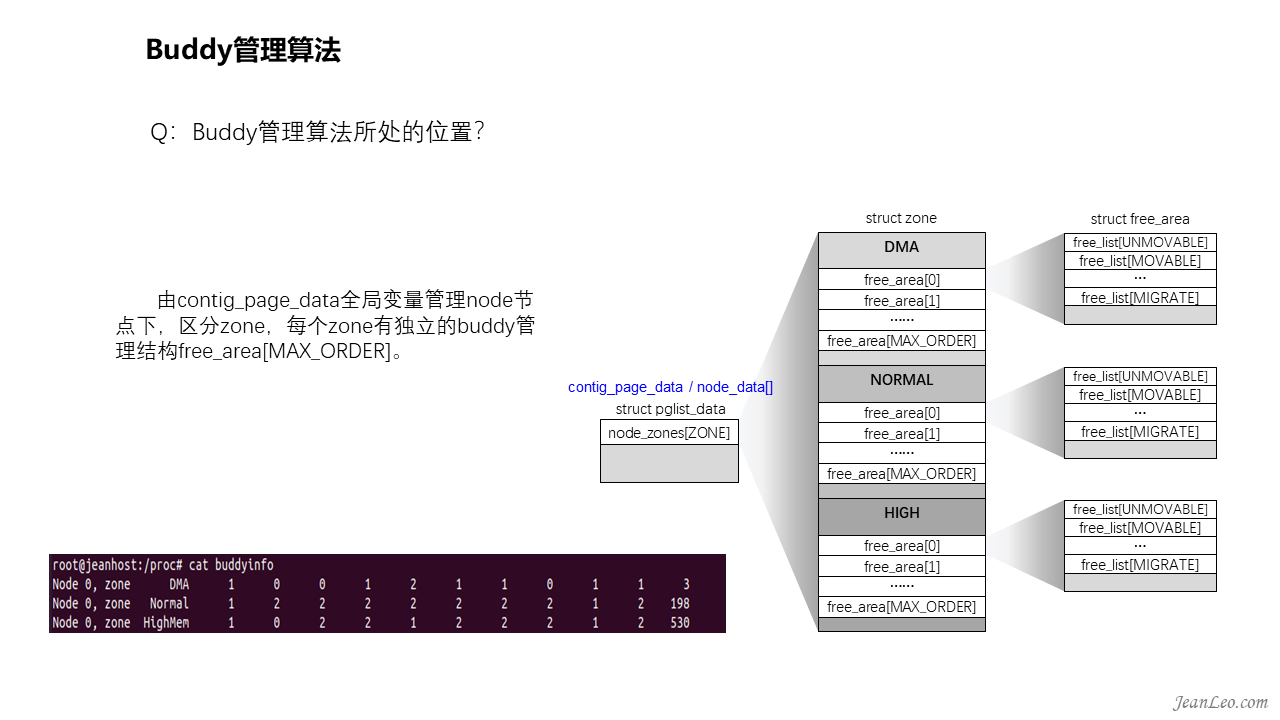
Buddy管理算法所处的位置?在什么地方体现?
如前面的NUMA管理框架所言,由Node到zone,所有内存页面归在zone的管理。所以buddy算法的管理结构在每个zone下面都有一个。由node管理结构struct pglist_data下,存在着一个struct zone数组结构,接着每个struct zone都有着自己独立的buddy管理结构free_area[MAX_ORDER],这是一个struct free_area结构数组。不过这还没完,每个struct free_area下面又根据内存页面的迁移类型进行分类管理,每个类型有着自己独立的链表。这些类型有什么用呢?这就涉及到接下来的内存页面迁移特性了。此外补充一句,对于buddy管理的内存页面状况,可以通过/proc/buddyinfo接口查看,它呈现了按阶分布的页面块统计。
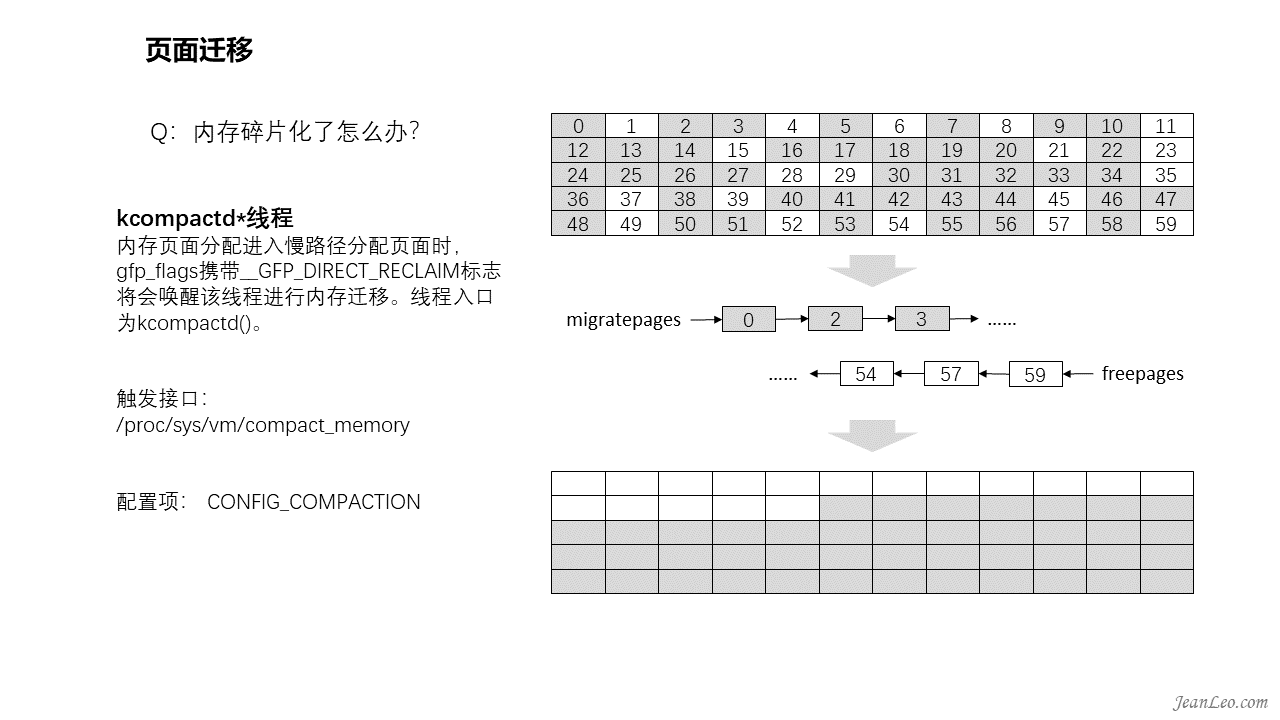
内存碎片化了怎么办?
虽然buddy管理算法已经极力地避免了内存碎片化,但是系统长久运行,大小不一的物理内存分配,终究还是会将内存拖进碎片化的深渊,犹如右上图。此时如果有设备驱动需要连续的物理内存怎么办?于是就有了页面迁移的功能。回归前面提及的内存页面类型是由enum migratetype定义的,主要有MIGRATE_UNMOVABLE,表示不可移动,针对的是kernel分配的内存页面;MIGRATE_MOVABLE,表示可移动,来自于从用户空间分配的内存和文件;MIGRATE_RECLAIMABLE,不可移动,但可以进行回收的;此外还有MIGRATE_PCPTYPES、MIGRATE_CMA和MIGRATE_ISOLATE等,其中MIGRATE_PCPTYPES表示该内存页面处于percpu中,而MIGRATE_CMA和MIGRATE_ISOLATE则是用于连续内存分配中使用的。至于内存页面迁移,主要涉及的就是可移动页面的处理,而且是针对zone来进行的。当内存分配过程中,无法满足分配需求时,将会唤醒kcompactd线程执行迁移动作,或者直接通过echo 1 > /proc/sys/vm/compact_memory来触发。其实现主要是通过freepages空闲链表和migratepages迁移链表实现的,其中自后往前检索空闲块插入空闲链表,自前往后检索可迁移块插入迁移链表。当前后两检索碰头时,表明全部页面检索完毕,由此可以将可迁移的内存块往空闲块上拷贝,将空闲页面汇聚到zone的前面去,碎片化也由此得到了消减。
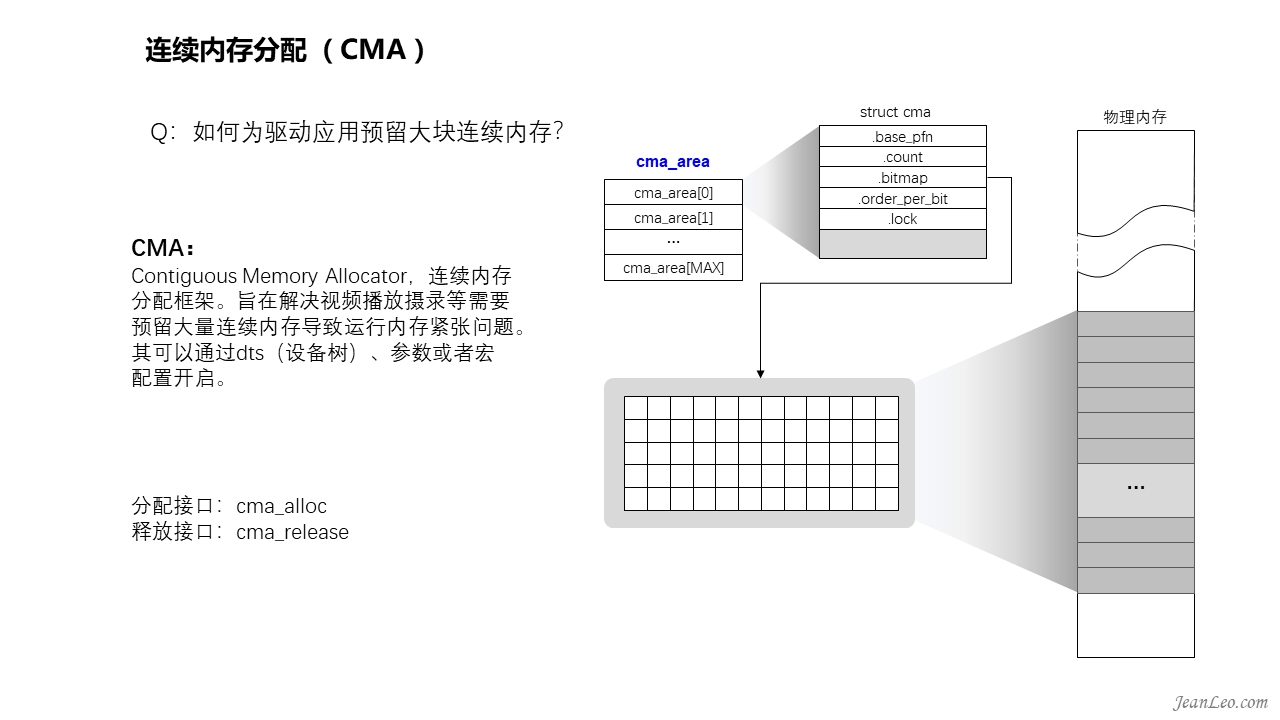
如何为驱动应用预留大块连续内存?
CMA:Contiguous Memory Allocator,连续内存分配框架,它是在前面的页面迁移功能的基础上实现的。旨在解决视频播放摄录等需要预留大量连续内存导致运行内存紧张问题。其可以通过dts(设备树)、参数或者宏配置开启。虽然有分配(cma_alloc())和释放(cma_release())接口的定义,但是通常不会直接使用,更多的是嵌入到DMA中使用。它虽然标记了内存空间,但是并不会独占,当分配migration类型内存时,会将其分配出去。分配出去之后如何需要使用的话,将会把其空间中已分配给migration的内存迁移走,给它腾出空间来进行分配,典型的一鱼多吃。
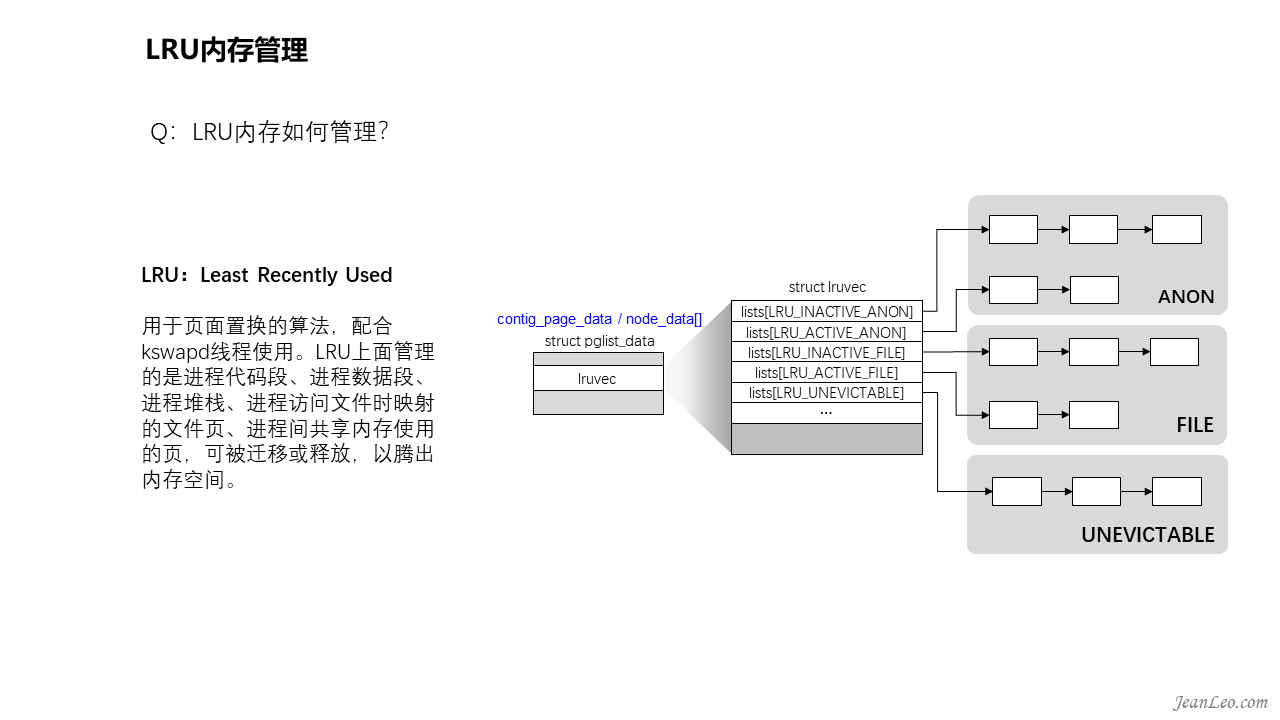
LRU如何运作?
LRU,Least Recently Used,最近最少使用内存。是用于页面回收置换的算法,配合kswapd线程使用。其本质就是一个在node下面lruvec结构内的链表,这链表主要用于管理三种类型的内存,分别是:匿名页,即没有与磁盘文件存在任何映射关系的内存页面,通常是进程的堆栈、数据段或共享内存空间;文件页,即与磁盘文件存在映射关系的内存页,例如进程代码段、文件的映射页等;不可换出页,通常为内核的代码数据段、内核栈及大部分内核使用的内存,或者干脆是被锁定的页面。然后在匿名页和文件页中,分别分为INACTIVE和ACTIVE两类属性链表,如果内存页经常被读写访问的情况下,将会放到ACTIVE链表中,反之放在INACTIVE链表中。
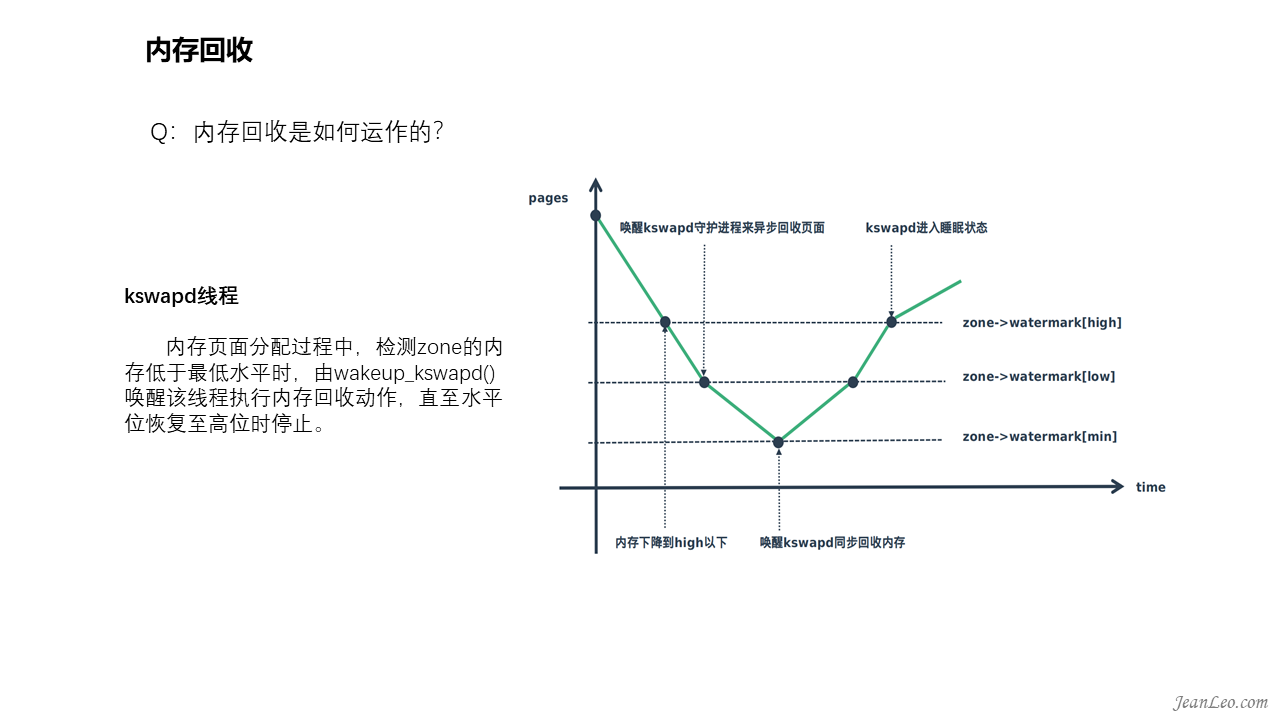
内存回收是如何运作的?
安装操作系统的时候,通常有个swap磁盘空间的大小设置和创建,那么这个swap空间作何使用?这就涉及到了内核的内存交换线程kswapd,这是一个常规性睡眠的内核线程,仅当内存开销达到临界点时触发。在此之前,我们需要知道struct zone结构中存在着一个数组变量watermark,它包含着三组数据WMARK_MIN、WMARK_LOW和WMARK_HIGH,分别表示该zone在运行时的最低、低和高三个水平。随着zone的内存陆续分配出去之后,空闲空间量缓慢下降,将会通过HIGH下降至LOW,此时将会唤醒kswapd线程对内存进行异步回收。如果kswapd线程因休眠等状况使得空闲空间触及WMARK_MIN最低量时,将会直接唤醒kswapd同步回收内存。kswapd线程主要通过kswapd()函数调用balance_pgdat()来完成回收动作,整个回收过程会持续到内存空闲量恢复至WMARK_HIGH最高水平才会进入休眠。至于这里所谓的回收,主要有:1、将磁盘文件映射占用的内存直接释放;2、匿名内存映射转储到swap磁盘分区。这是因为磁盘文件有磁盘作为存储介质,因此可以直接释放掉,需要时重新映射回内存中,当然如果文件映射内存被改写后成为脏页则需写回磁盘后方可释放。至于匿名页为进程运行所需的内存,但是又没有直接对应的磁盘文件可回写备份,因此需要放到swap分区中临时备份。
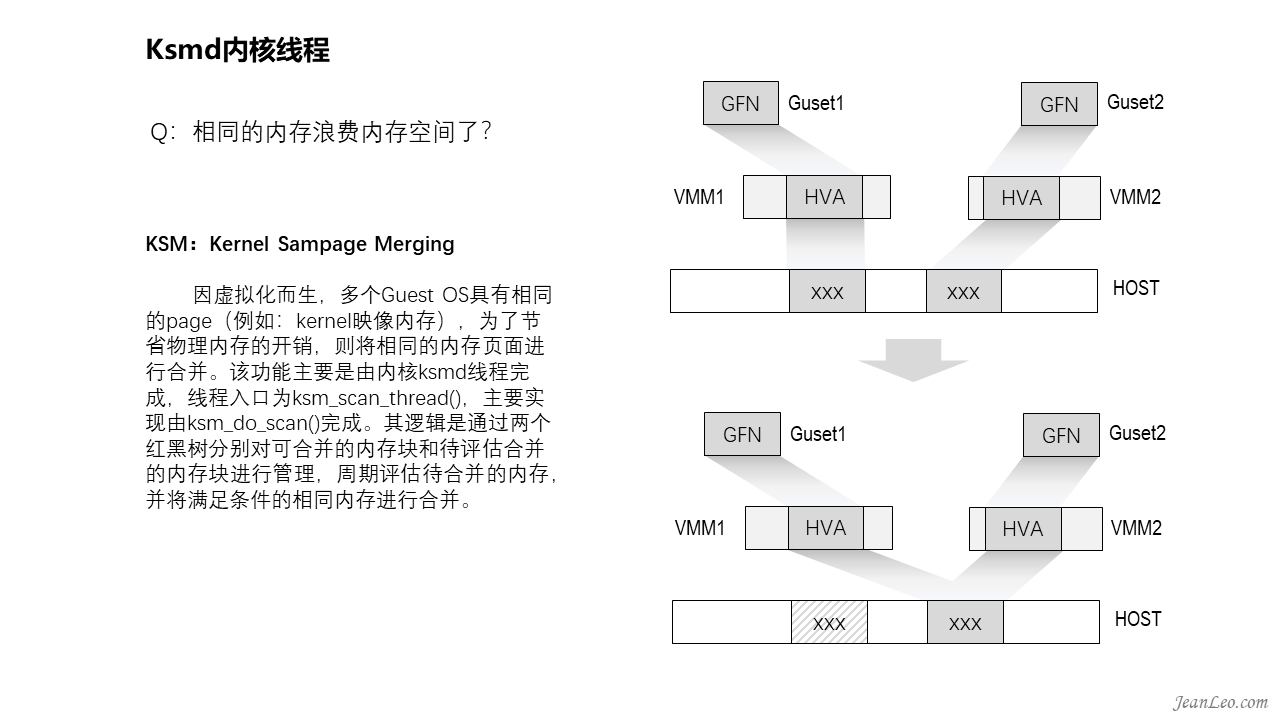
相同的内存浪费内存空间了?
对于文件映射到物理内存上,由于文件都由内核统一管理,多个进程读取同一个文件相同片段时,内核实际只在物理内存上存了一份数据,各个进程的映射表都修改映射指向它,除非写时拷贝复制出去的。于是对于文件这类的映射访问对内存的开销是有限的。但是对于虚拟化而言,多虚拟机运行,有很多虚拟机的匿名映射的内存页面其实是完全相同的,它与文件毫无关联,所以内核不知道它们相同,也没法将它们统一到一份物理映射上。为了解决这个带来的内存浪费,于是引进了KSM功能,有人称之为Kernel Samepage Merging,也有人称之为Kernel Shared Memory。其作用就是将完全相同的匿名内存页面的映射归一,即通过修改内存映射,共同使用同一份物理内存,如果出现修改时,则通过写时拷贝解决差异问题。该功能主要是由内核ksmd线程完成,线程入口为ksm_scan_thread(),主要实现由ksm_do_scan()完成。其逻辑是通过两个红黑树分别对可合并的内存块和待评估合并的内存块进行管理,周期评估待合并的内存,并将满足条件的相同内存进行合并。
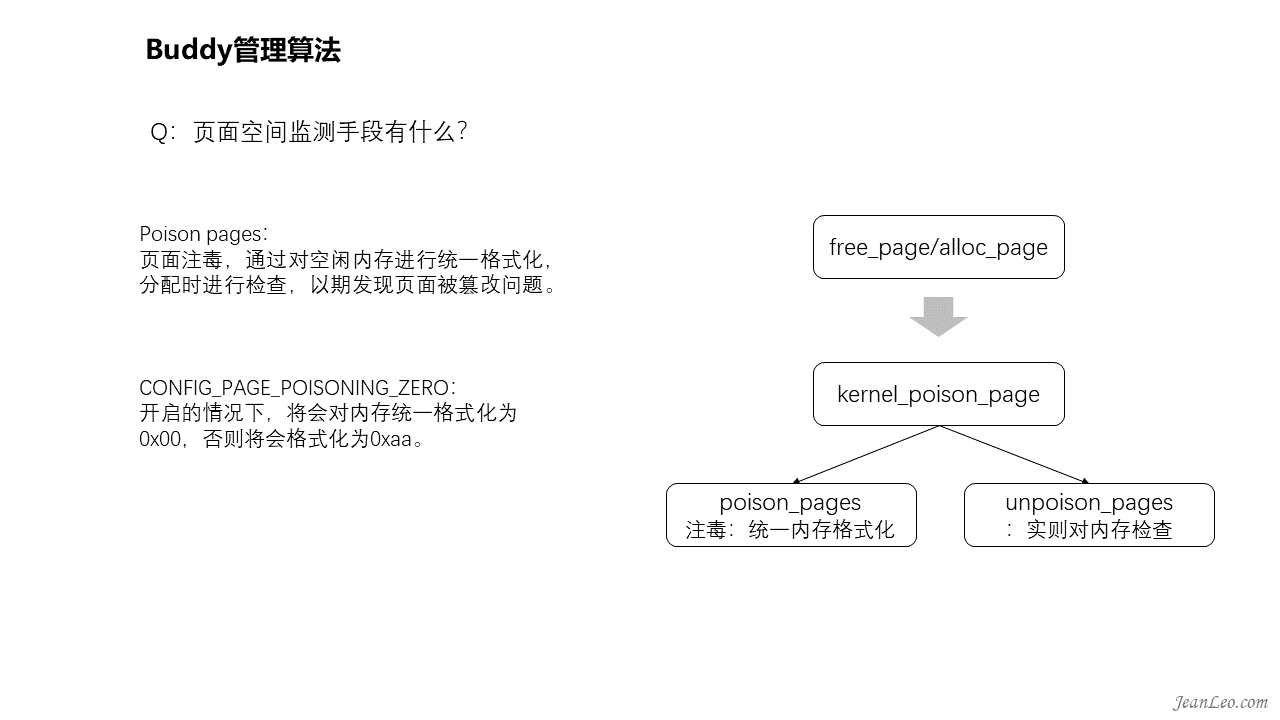
页面空间监测手段有什么?
Poison pages,页面注毒,通过对释放的空闲内存进行统一格式化,要么格式化成为0x00,要么格式化为0xaa,则取决于配置项CONFIG_PAGE_POISONING_ZERO。格式化之后的内存当再次分配时将进行检查,如果检测到内存空间存在非格式化的数据时,则表明该内存曾在空闲时被修改,这就意味着发生了内存越界或内存释放后使用等类似情况,同时将被篡改的数据记录到日志中。该功能实现很简单,在内存页面释放free_page流程或者分配alloc_page流程都会调用到kernel_poison_page(),只是调用传参不同,以表示当前动作是释放内存页面还是分配内存页面,然后分别调用注毒和解毒函数。所有的格式化和检测上报功能都是在该函数内完成。
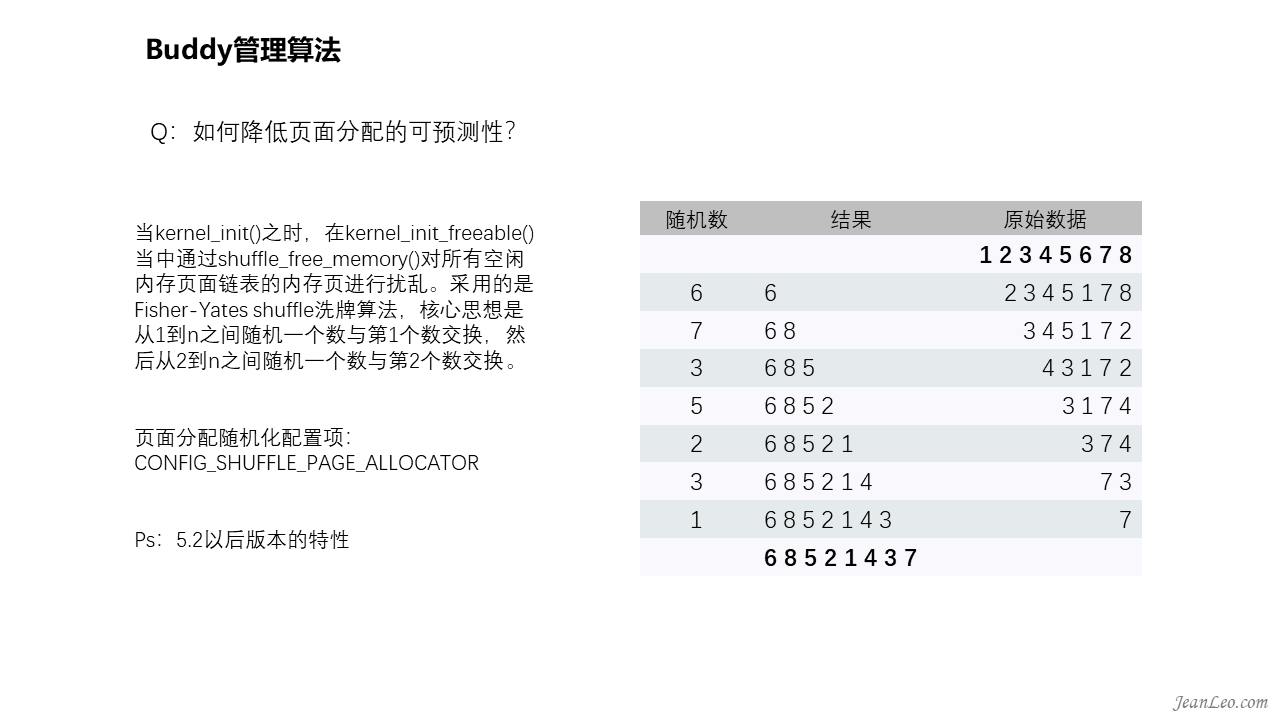
如何降低页面分配的可预测性?
当kernel_init()之时,在调用kernel_init_freeable()当中通过shuffle_free_memory()对所有空闲内存页面链表的内存页进行扰乱。采用的是Fisher-Yates shuffle洗牌算法,核心思想是从1到n之间随机一个数与第1个数交换,然后从2到n之间随机一个数与第2个数交换,如右侧图所示的顺序进行洗牌扰乱。可以通过配置项CONFIG_SHUFFLE_PAGE_ALLOCATOR开启页面分配随机化该功能,除此之外还可以通过接口文件shuffle进行设置,该接口文件将会调用到page_alloc_shuffle()函数进行设置。不过这页面扰乱是5.2以后版本才有的特性。
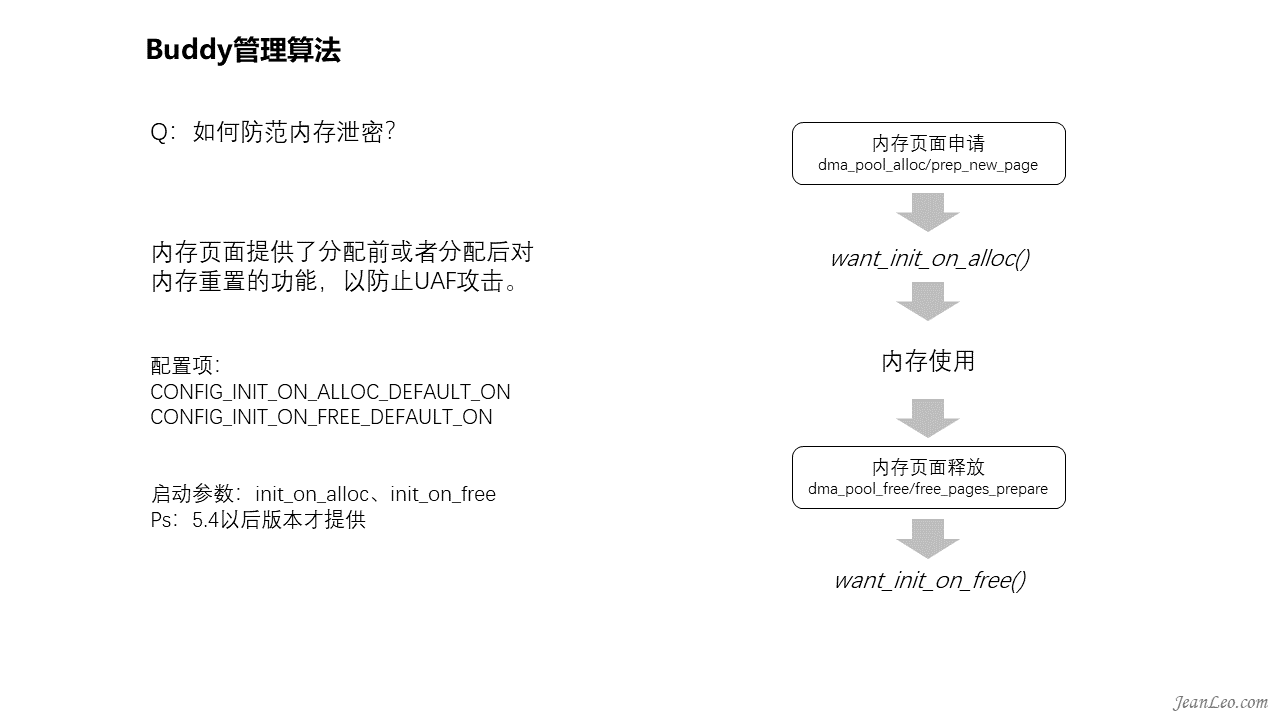
如何防范内存泄密?
内存页面提供了分配前或者分配后对内存重置的功能,以防止UAF攻击。当内存页面分配返回前,将会调用want_init_on_alloc()函数,该函数将会判断init_on_alloc变量是否为true,如若开启将会对分配的内存进行为0的格式化,该功能可以通过CONFIG_INIT_ON_ALLOC_DEFAULT_ON配置项控制。内存格式化?这个听起来和前面提到的poison pages很相似?是的,实现上是相近的,但是该功能不会对内存进行检测,仅是格式化而已。此外该功能与poison page相冲突,如果poison page开启,此功能失效。同样,want_init_on_free()则是在内存页面释放时通过want_init_on_free()判断检测init_on_free变量,对应配置项为CONFIG_INIT_ON_FREE_DEFAULT_ON。此外也可以通过kernel的启动参数init_on_alloc和init_on_free进行控制。
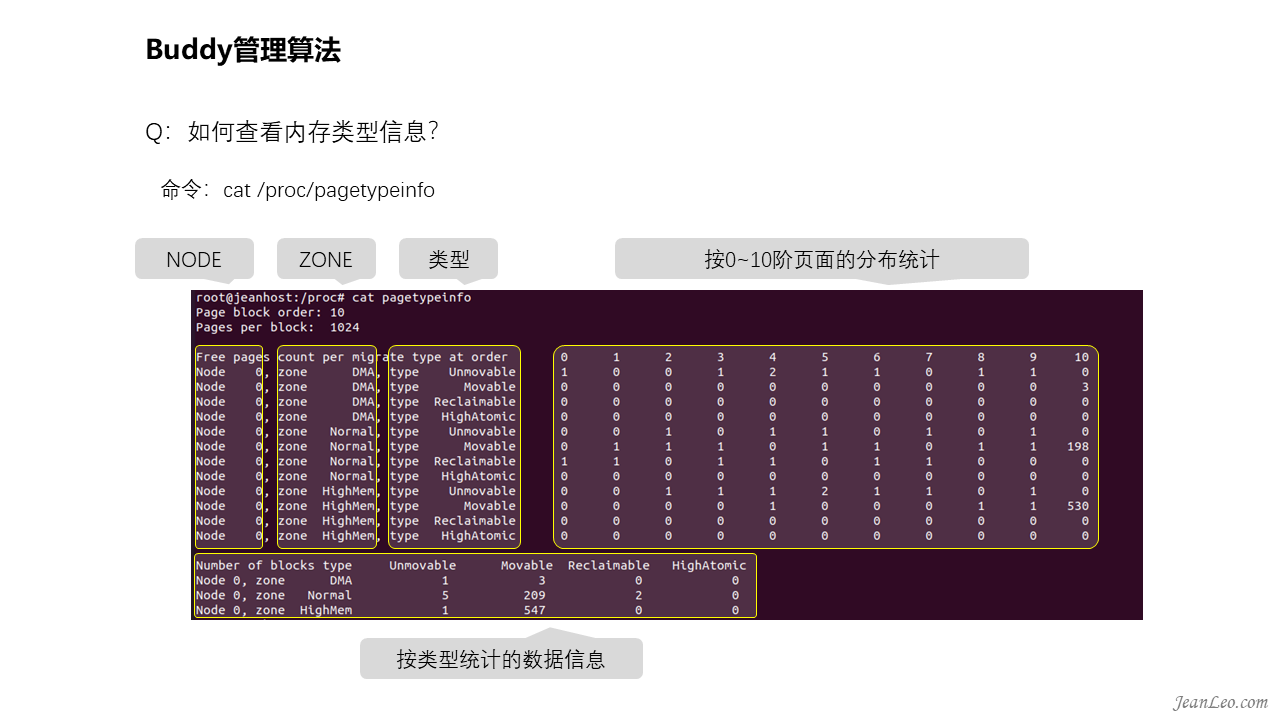
如何查看Buddy管理算法下的内存类型信息?
对此,我们可以通过/proc/pagetypeinfo接口文件进行查看。通过该文件,可以看到各个node的zone下面,以类型划分,从0到10为阶的页面大小的统计情况。同时还提供了汇总数据。

小块内存空间如何分配管理?
小块内存采用的是slab算法。slab算法共有三种:SLAB、SLUB、SLOB,原因是SLAB最早出现,而SLOB和SLUB是后面出现的,但是继承了SLAB的接口定义,所以现在都倾向于对该类型内存算法称为slab,实际上各有所长。SLAB是最早出现的分配算法,内存块管理采用的是红黑树;而SLOB是针对嵌入式场景而优化的,资源开销最小;至于SLUB则是现在主流算法,是针对SLAB的改良。三种算法的接口统一,也就意味着不能共存,内核编译时可以通过配置选项来控制选择何种算法。而slab的分配出来的内存被称之为object对象。
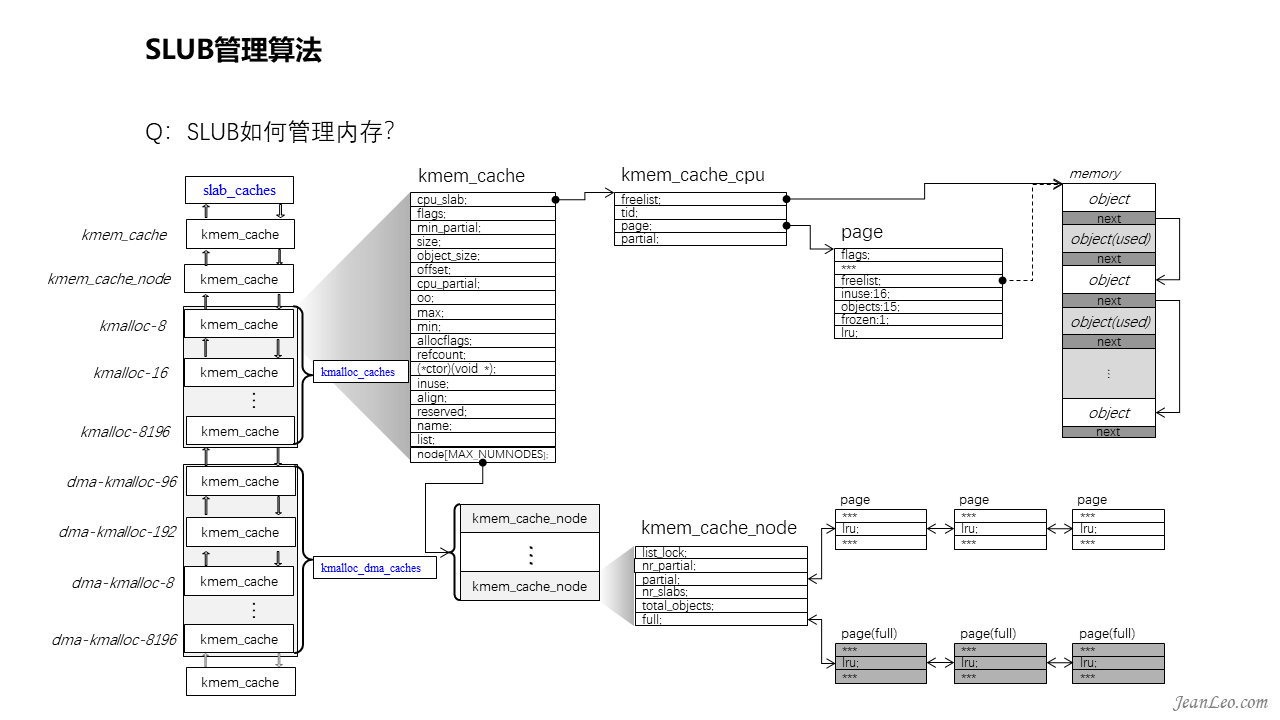
SLUB如何管理内存的?
Slub分配管理中,每个CPU都有自己的缓存管理,也就是kmem_cache_cpu数据结构管理;而每个node节点也有自己的缓存管理,也就是kmem_cache_node数据结构管理。分配的时候,如果CPU的缓存存在满足条件的freelist空闲链表不为空时,则直接取出一个对象分配出来。如果CPU缓存为空,那么先会向buddy算法申请内存页面,接着将分配的内存页面空间分割成一个个对象并放入到node节点中,然后填充CPU缓存,最后再从CPU分配出去。但是释放流程就复杂多了,它需要考虑到释放的对象和CPU的缓存对象是否来自同一个内存页面,然后放到CPU缓存还是还回到node节点中,而且还需要考虑缓存对象过多时往buddy算法归还内存的情况。所以释放流程实现会复杂一些,这里就不展开了。总而言之,SLUB、SLOB、SLAB就是一个批发零售商的角色,从buddy算法中批发内存然后零售。

如图,可以通过/proc/slabinfo查看slab信息。
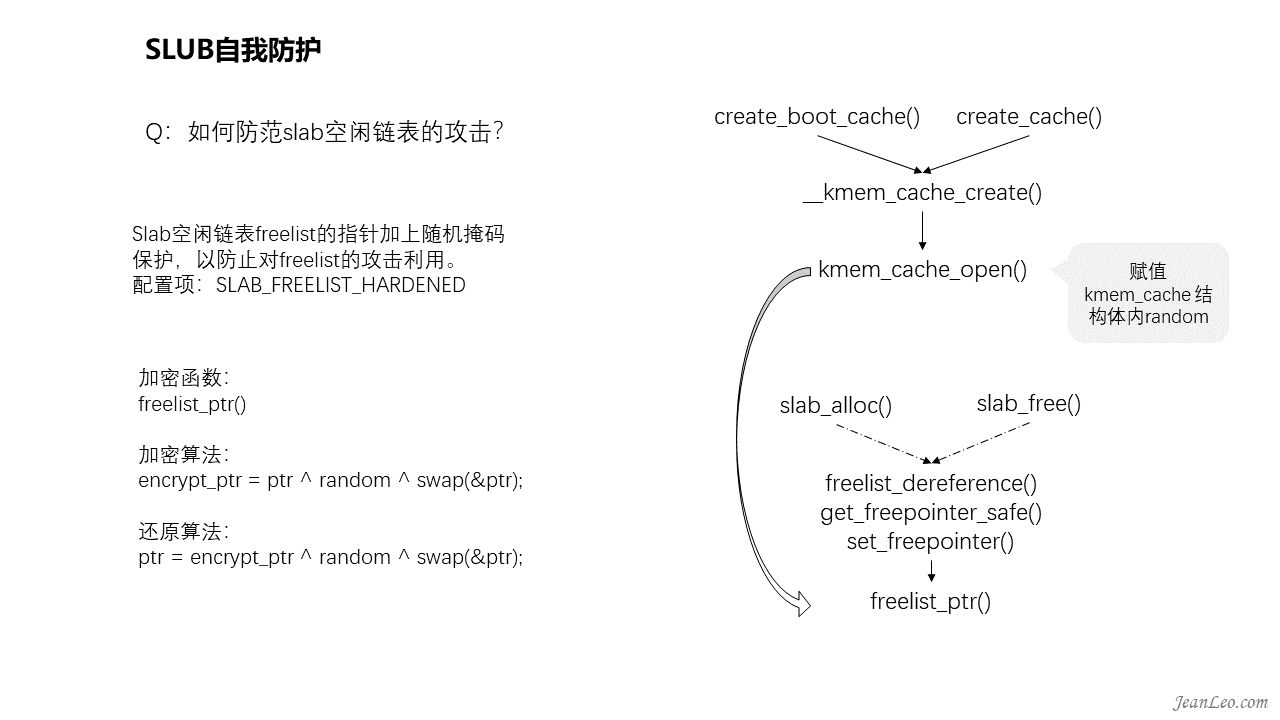
如何防范slab空闲链表的攻击?
Slab空闲链表freelist的指针加上随机掩码保护,以防止对freelist的攻击利用。主要实现是在由slab的分配接口slab_alloc()和释放接口slab_free()均会调用到的freelist_dereference()函数进去间接调用到freelist_ptr()里面完成。通过encrypt_ptr = ptr ^ random ^ swap(&ptr)算法完成加密,其中random数值来自于slab创建时生成的随机数,所以各个slab池各不相同。由此隐藏了slab空闲链表上的真实指针值,避免slab空闲链表的利用攻击。

SLUB分配如何防止被预判?
除了slab的freelist链表的地址隐藏外,其实还有链表的随机化,用于防止被预测攻击。在初始化之时,init_cache_random_seq()通过构造slab的map数组,扰乱数组编号,再乘以slab的大小构造成slab池的offset地图。然后到了创建新slab池之时,则会在shuffle_freelist()中将通过随机数从map数组中随机挑选一个作为freelist的头部,继而由此往后遍历,将所有块串到一块去。如右图所示。该功能可以通过配置项CONFIG_SLAB_FREELIST_RANDOM控制开启。但仅限于扩展slab池的随机化,最早初始化创建slab池的时候是没有随机化功能的。
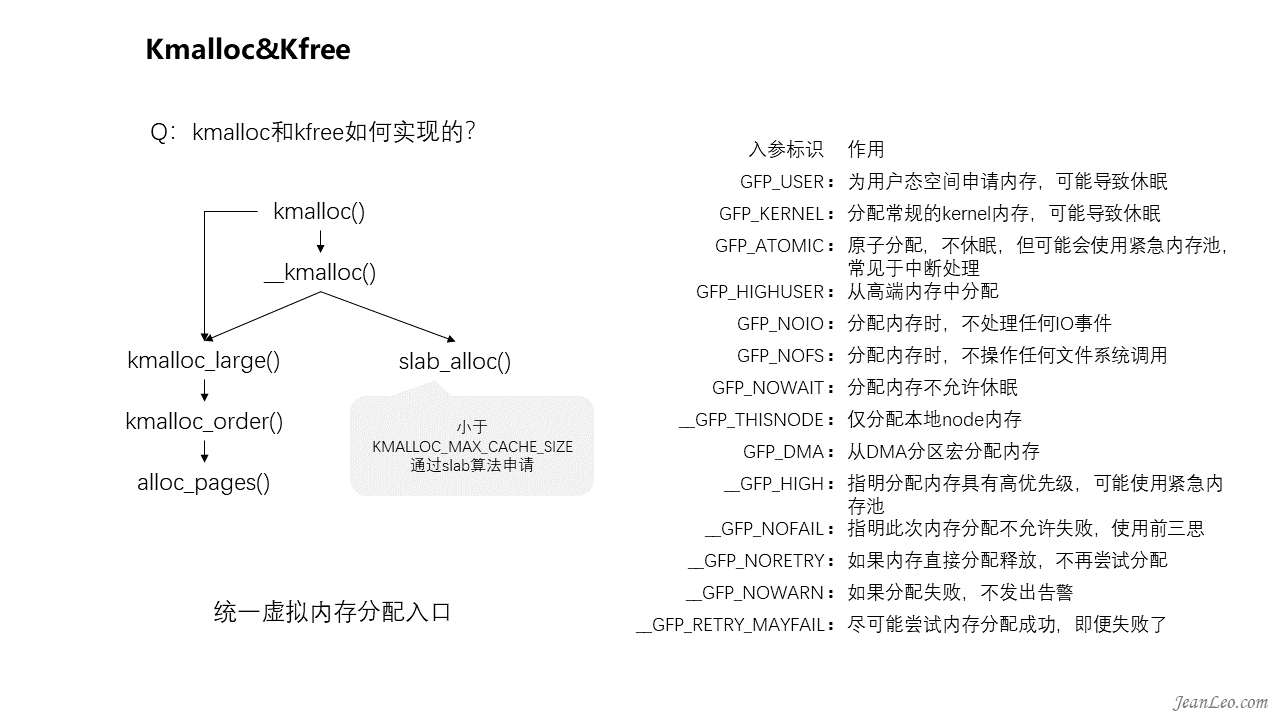
kmalloc和kfree如何实现的?
kmalloc和kfree实际上是没有管理算法实现的,它只是实现了统一化入口,提供丰富的控制参数,便于内核开发者使用。对于小于KMALLOC_MAX_CACHE_SIZE的内存,将会通过slab算法申请,否则都会进入到page页面分配流程,即buddy算法管理的物理页面。
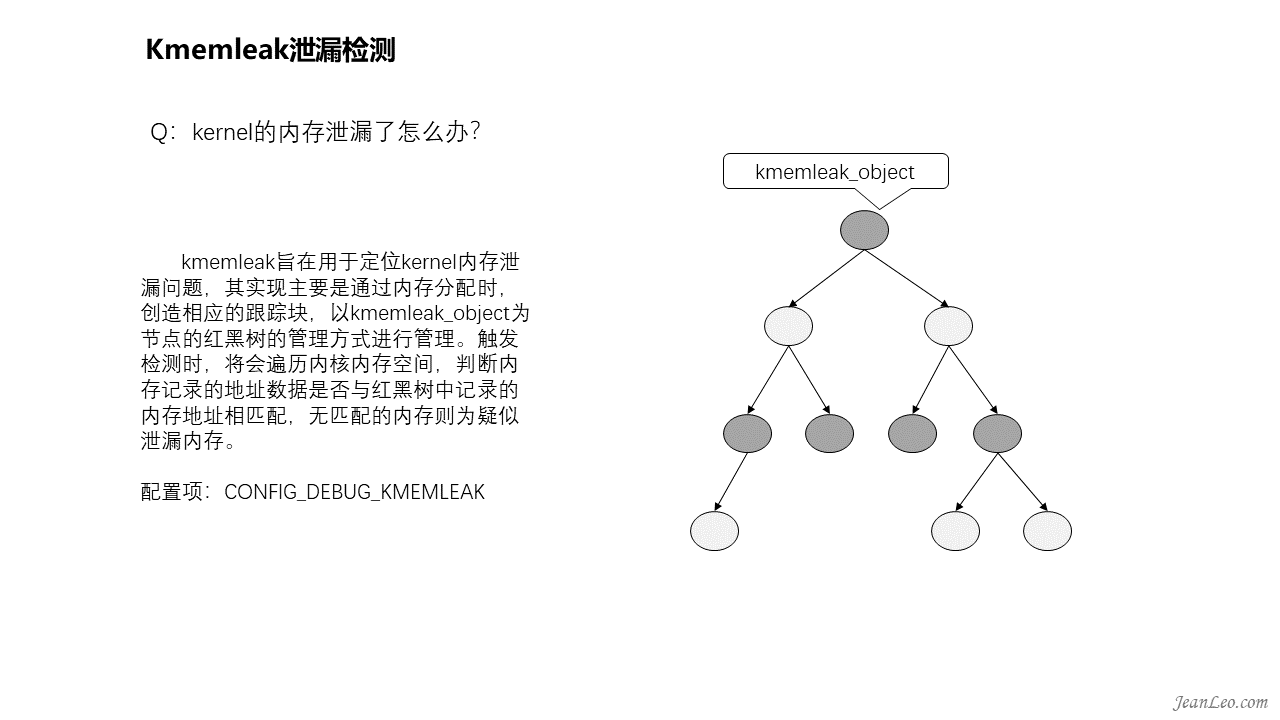
kernel的内存泄漏如何定位?
大概在2.6之前的内核版本,就已经存在一个内存泄漏检测机制,称之为kmemleak,相应的配置选项为CONFIG_DEBUG_KMEMLEAK。该功能旨在用于定位kernel内存泄漏问题,它的实现主要是通过内存分配时,创造相应的跟踪块,以红黑树的管理方式进行管理。触发检测时,将会遍历内核内存空间,判断内存记录的地址数据是否与红黑树中记录的内存地址相匹配,无匹配的内存则为疑似泄漏内存。整个实现与Java的垃圾回收机制中的内存检测相似,但对kernel而言,该功能仅检测不回收。
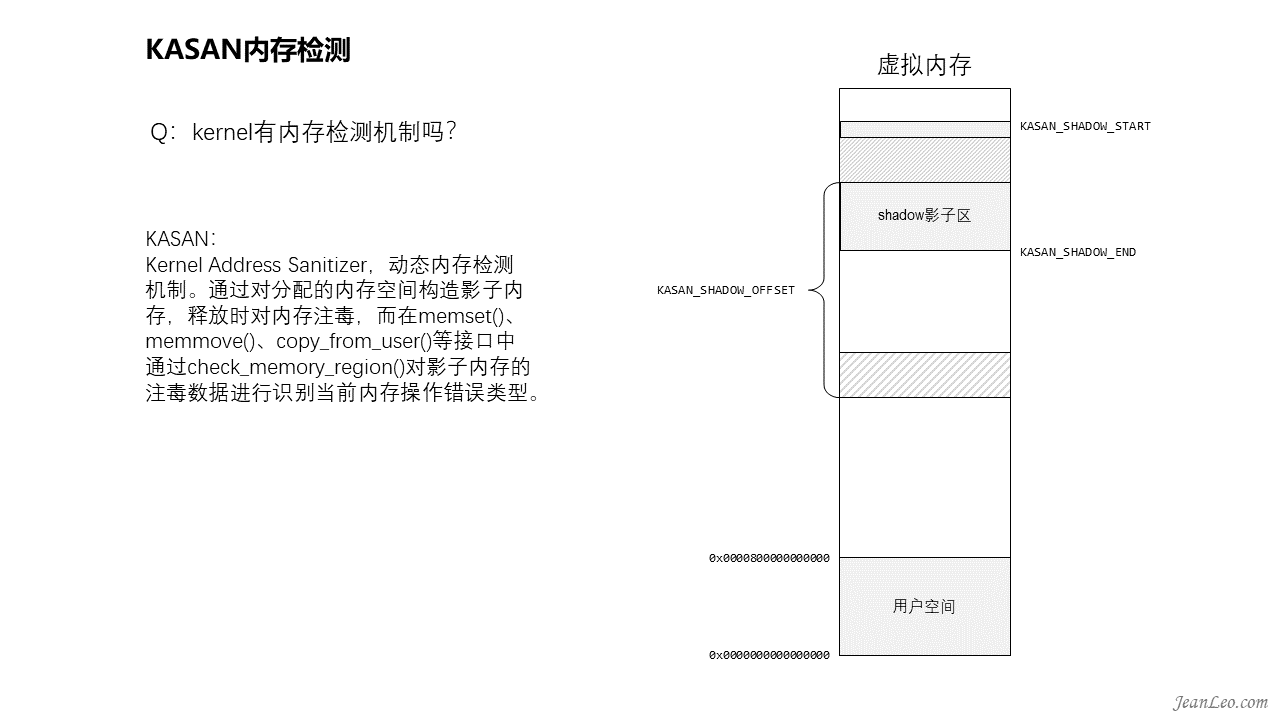
kernel有内存检测机制吗?
除了内存泄漏检测机制kmemleak还有别的检测机制吗?有的,就是KASAN,Kernel Address Sanitizer,动态内存检测机制。通过对分配的内存空间构造影子内存,即与分配的内存大小相同且有一一对应关系的内存空。通过偏移量KASAN_SHADOW_OFFSET即可访问到影子内存。通过申请和释放时对影子内存注毒,也就是使用代表内存分配和释放状态的不同值来格式化影子内存,而在memset()、memmove()、copy_from_user()等接口中通过check_memory_region()对影子内存的注毒数据进行识别当前内存操作错误类型。例如拷贝的内存是否为已释放的内存,如果是,则表示可能发生了越界或UAF。这里影子内存主要针对内存页面及slab内存,当然还可以通过__asan_register_globals()去扩展到对全局变量的检测。
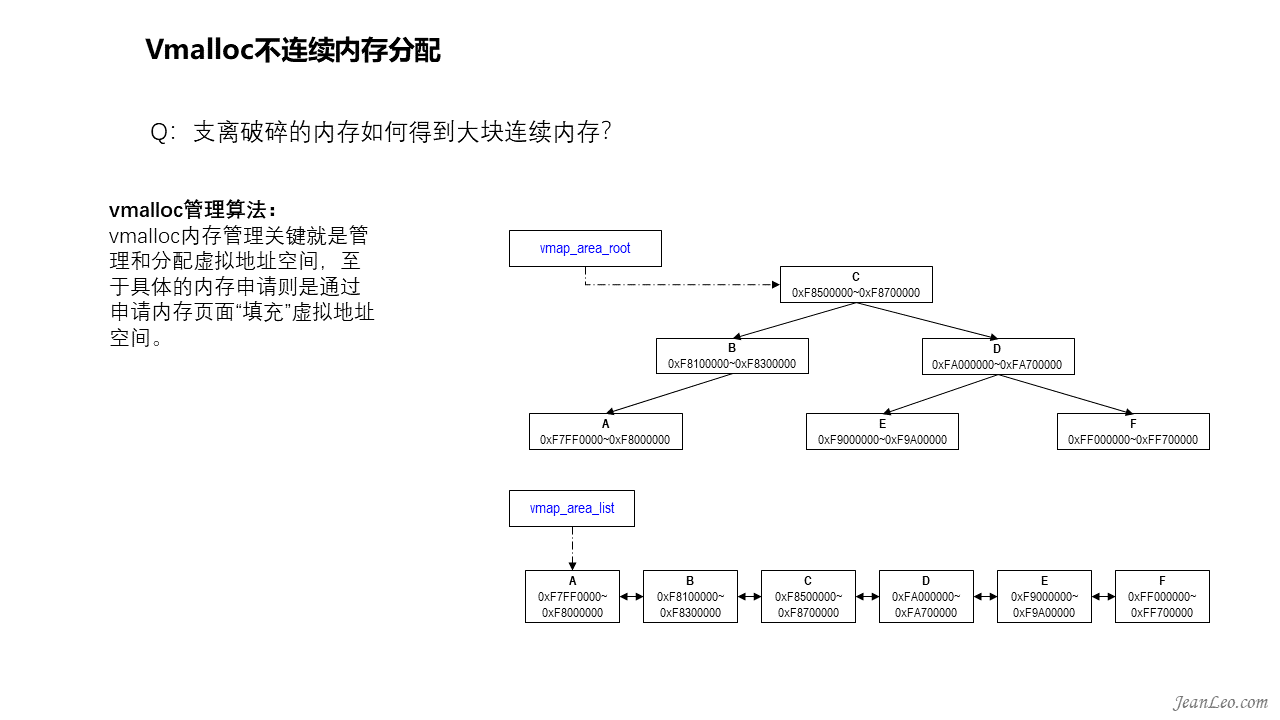
支离破碎的内存如何得到大块连续内存?
vmalloc的实现主要是通过__get_vm_area_node()从vmalloc空间中分配出一个空间大小相匹配的vm_struct结构虚拟地址空间,然后通过__vmalloc_area_node()循环申请页面填满申请的空间并将物理页面和虚拟地址空间映射起来,由此完成分配。vmalloc的管理核心结构为vmap_area,该结构既有数据成员rb_node处于红黑树中,又有数据成员list在链表中,双管理结构。其中链表在旧版本算法中还起到辅助查找虚拟地址空间的作用,现在最新版本已经沦为查询时候遍历的链表了。为了方便查找空闲的虚拟地址空间,新增了free_vmap_area_root,它是管理空闲虚拟地址空间的红黑树。分配虚拟地址空间的时候,将会从free_vmap_area_root查找合适的空间,然后插入到vmap_area_root红黑树中和vmap_area_list中。

如图,可以通过/proc/vmallocinfo查看vmalloc的信息。
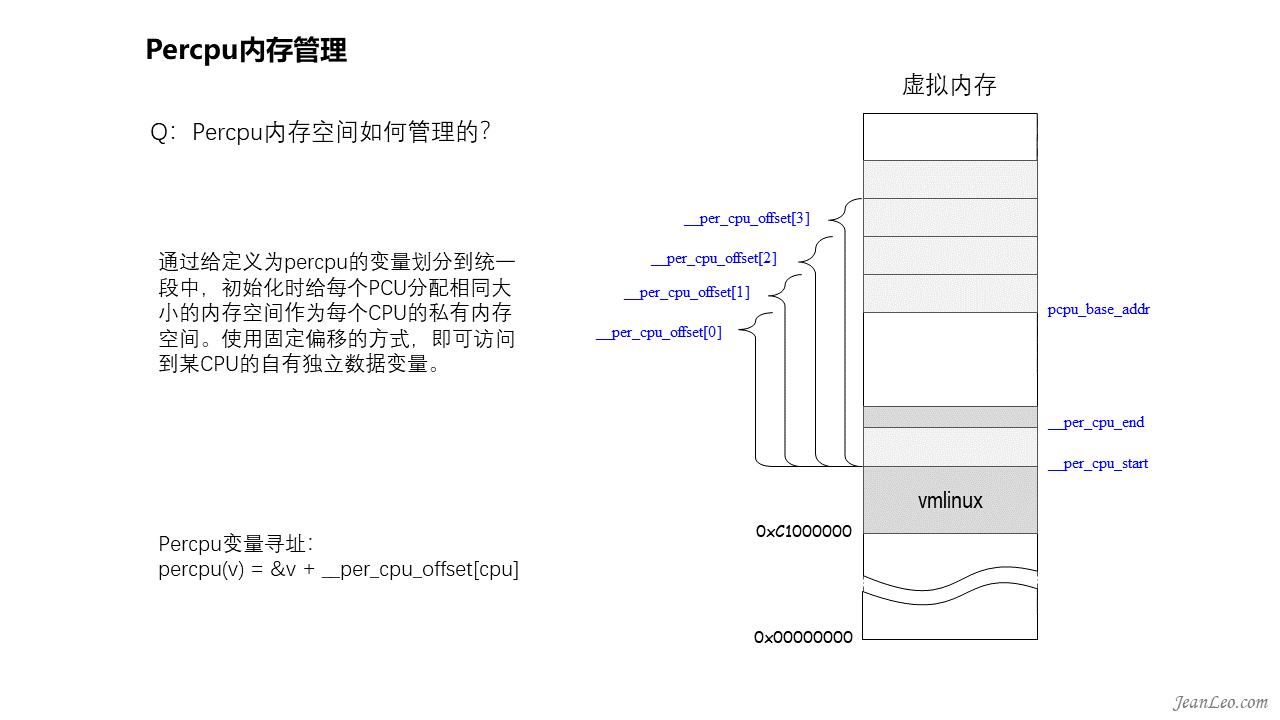
Percpu内存空间如何管理的?
为什么需要有percpu内存空间呢?这是针对CPU的缓存设计而来的,从主存到CPU有多级缓存,对各个CPU而言,有独占的缓存也有共享的缓存,如果要是对共享内存进行修改的话,那么硬件需要去使其他CPU上对应的缓存进行失效处理,由此对性能影响较大,尤其是一些CPU自己使用的私有变量。故此设计了percpu变量及内存,目的就是降低cache失效的频率,从而提高性能。那么这些percpu内存空间如何管理?它们是通过给定义为percpu的变量划分到统一段中,该段空间用__per_cpu_start及__per_cpu_end标明了起始位置,然后系统初始化时给每个CPU分配相同大小的内存空间作为每个CPU的私有内存空间。使用固定偏移__per_cpu_offset[*]的方式,即可访问到某CPU的自有独立数据变量。运行的时候,原始的percpu变量定义空间数据仅初始化时设置过而已,后面基本上是不会变的。

从proc接口可以看到什么?
/proc/meminfo
各种状态及类型的物理内存占用情况统计数据。
/proc/vmstat
各种状态及类型的虚拟内存页面数量统计信息。
/proc/zoneinfo
以zone为统计维度下,各种状态的内存页面占用量。
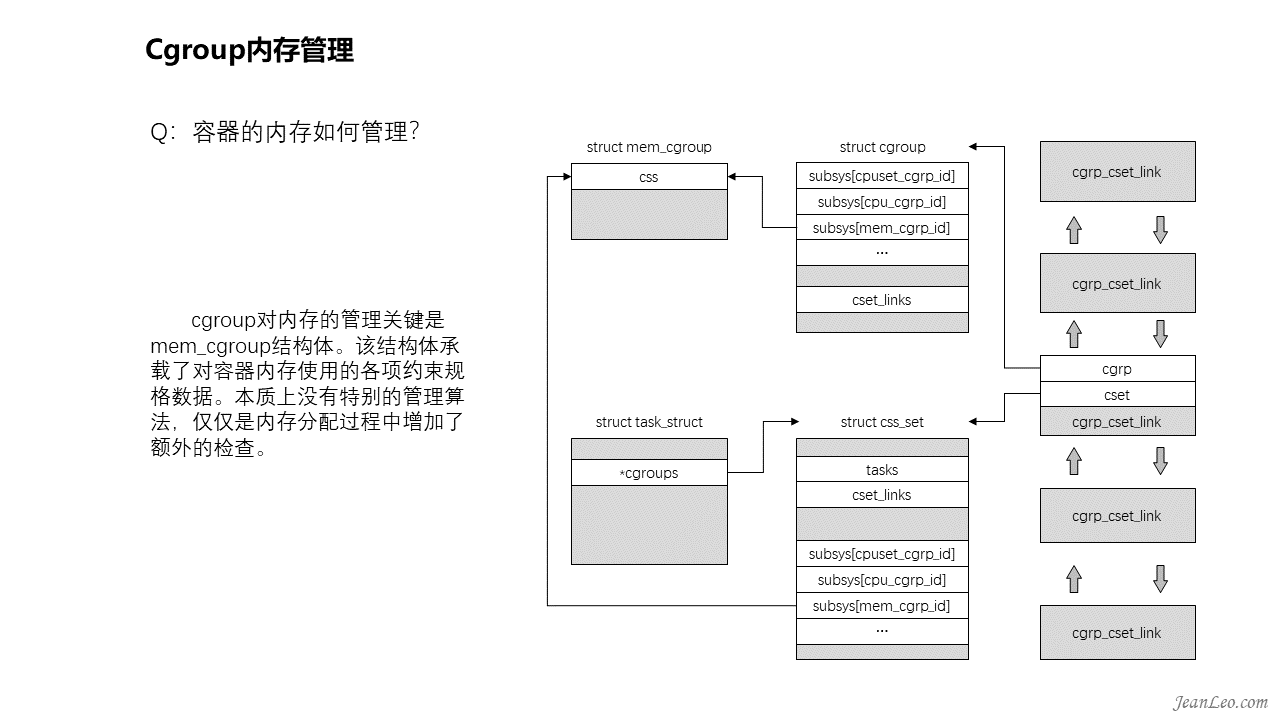
容器的内存如何管理?
cgroup对内存的管理关键是mem_cgroup结构体。该结构体承载了对容器内存使用的各项约束规格数据。本质上没有特别的管理算法,仅仅是内存分配过程中增加了额外的检查。cgroup和css_set是多对多关系,cgrp_cset_link链表将两者关联起来。一个cgroup可以有多个进程,一个进程也可以加入多个cgroup中。而mem_cgroup是cgroup的一个子系统,并且一个cgroup只能挂载一个子系统,但子系统却可以被挂载到多个cgroup中,前提是这些cgroup只能有这么一个子系统。由此就诞生了如此的关联关系。
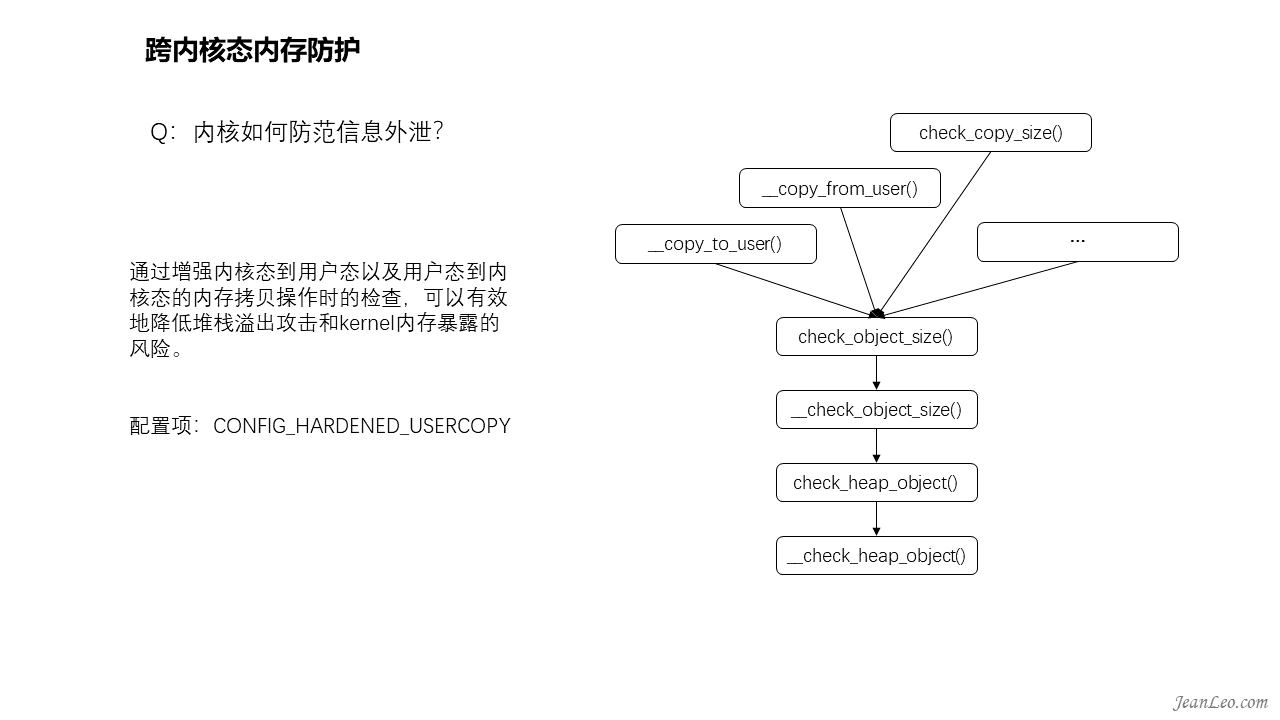
内核如何防范信息外泄?
通过增强内核态到用户态以及用户态到内核态的内存拷贝操作时的检查,可以有效地降低堆栈溢出攻击和kernel内存暴露的风险。其中check_object_size()作为一个入口,在多个跨用户态内核态的操作函数中存在调用点,例如:strncpy_from_user()、check_copy_size()、__copy_from_user_inatomic()、__copy_from_user()、__copy_to_user_inatomic()及__copy_to_user()。其中该功能最终实现防护判断的是__check_heap_object()函数,该函数主要识别拷贝的内存是否为不合理地址范围、是否完全处于slab对象范围内,如果存在越界的情况将会中止拷贝。
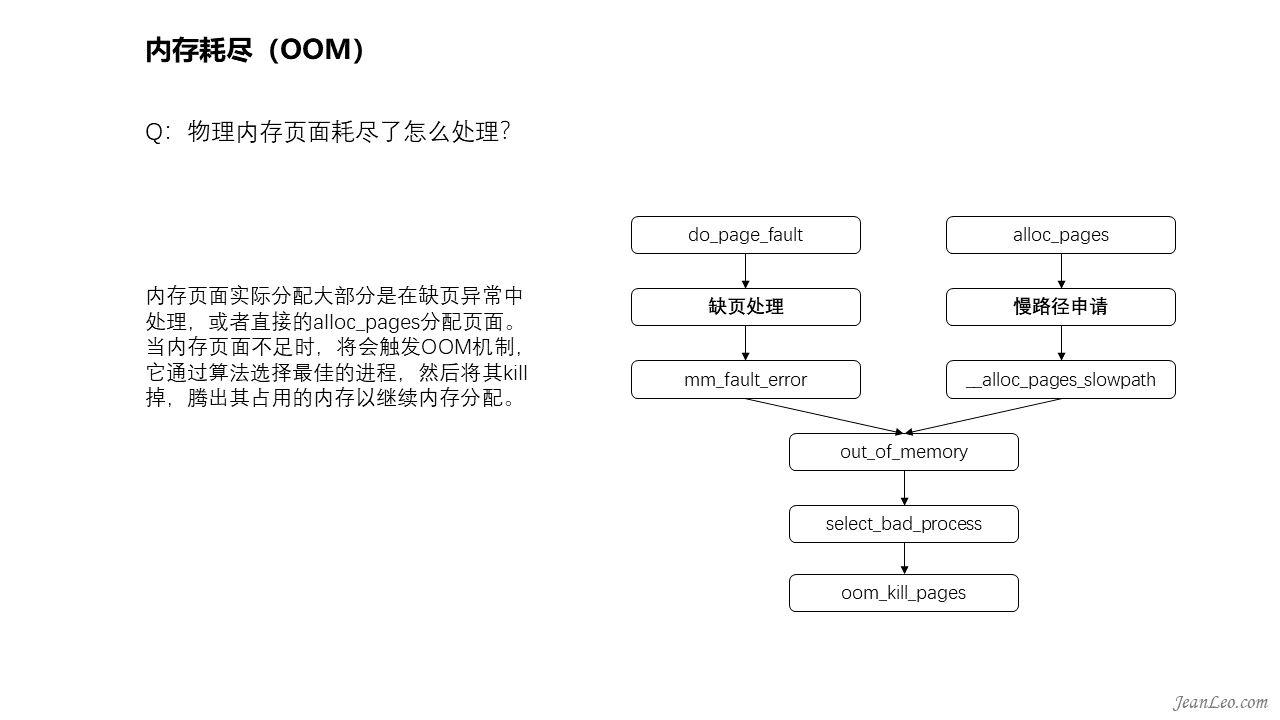
物理内存页面耗尽了如何处理?
内存页面实际分配大部分是在缺页异常中处理,或者直接的alloc_pages分配页面。当内存页面不足时,将会触发OOM机制,它通过select_bad_process()中的算法选择最佳的进程,然后使用oom_kill_pages()将对应进程kill掉,腾出其占用的内存以继续内存分配。
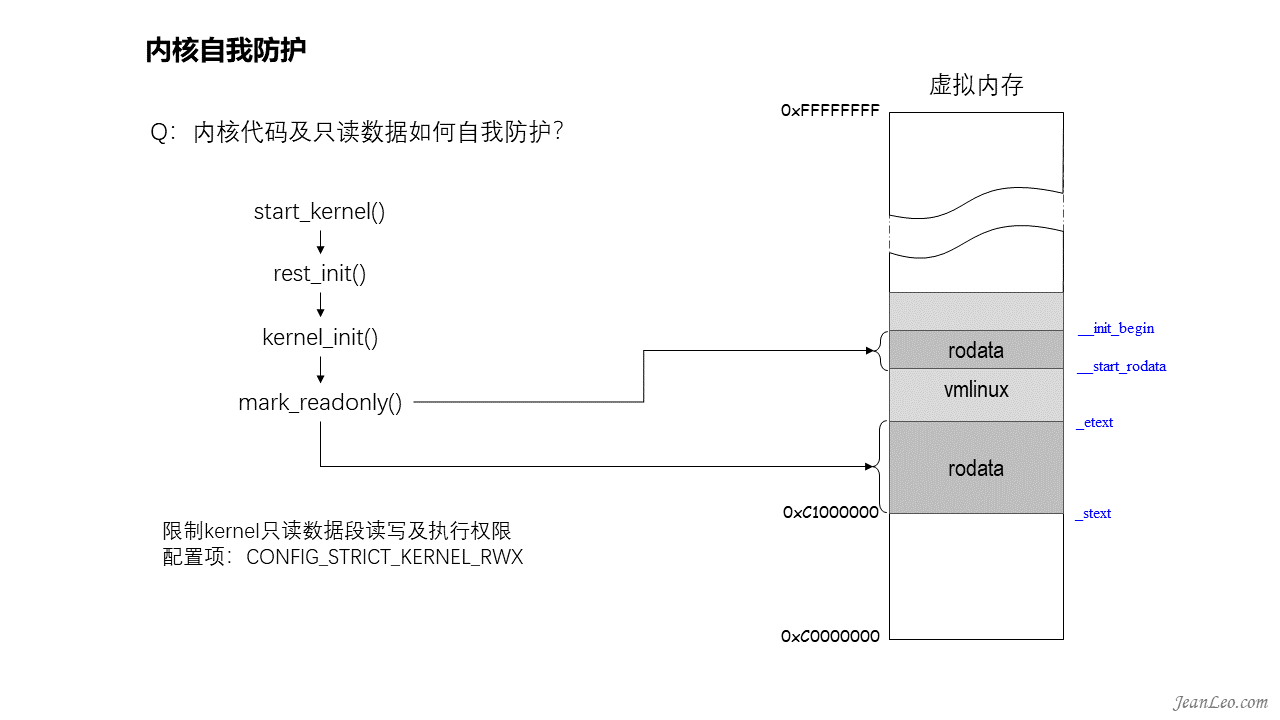
内核代码段如何进行自我防护?
内核启动start_kernel()执行完毕即将退出的时候,可以通过mark_readonly()函数对_stext到_etext标识的代码段以及__start_rodata到__init_begin标识的只读数据段的内存空间设置为只读,由此防范堆执行以及代码段修改等类型的安全漏洞。该功能可以通过CONFIG_STRICT_KERNEL_RWX配置项进行开启,但是它同时也限制了内核的软件断点,所以需要使用kdb的情况下需要关闭该功能。

内核代码段如何防护注入?
对内核代码段和只读数据进行内存只读保护设置mark_rodata_ro()收尾的时候,有一处debug_checkwx()函数调用,它将会对已经做了映射并且非系统程序的内存进行可写可执行检测。如果检测到存在该类型内存空间,将会记录至dmesg中。这里检测到此类内存空间的存在,并不表示该内存空间一定是一个安全漏洞,但是一个潜在的安全风险。该功能的作用主要是及早暴露这些易于被利用的未修复的内核模块。该功能由CONFIG_DEBUG_WX配置项控制开启,且依赖于前面讲述的CONFIG_STRICT_KERNEL_RWX文本及只读数据的只读设置。
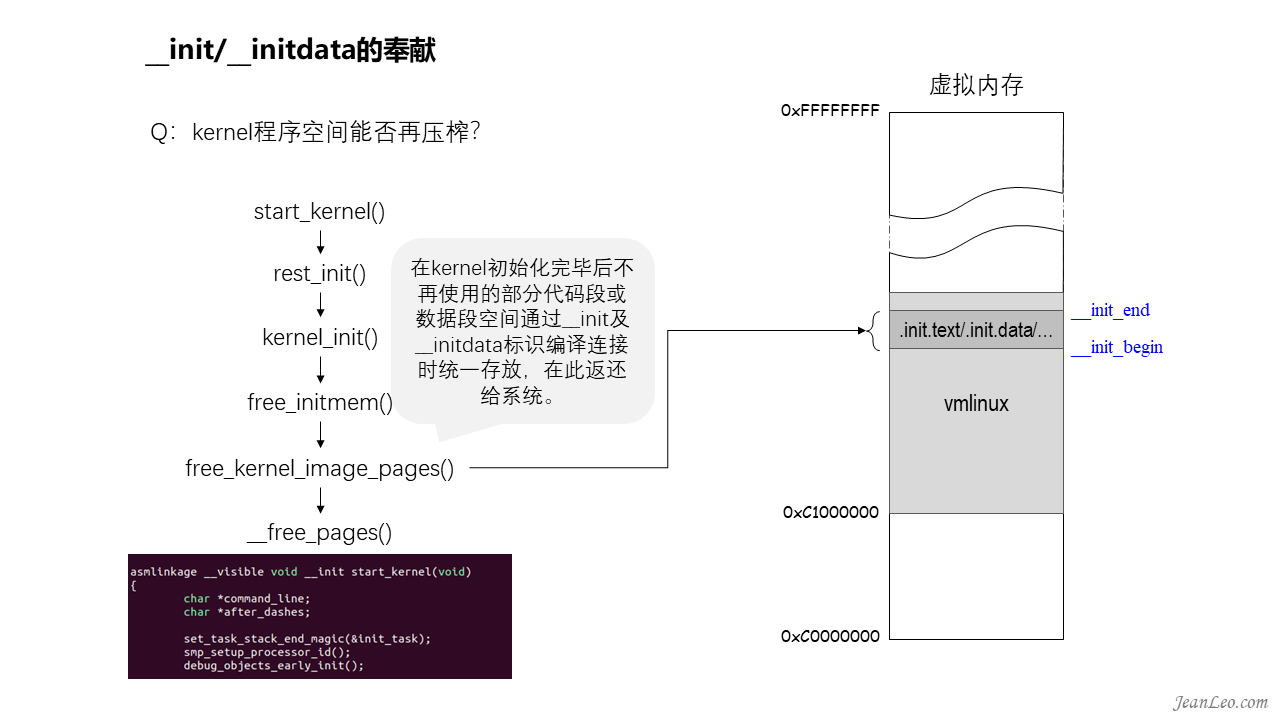
kernel程序空间能否再压榨?
为了尽可能地压缩kernel程序占用的内存空间,内核设计了__init及__initdata属性定义,用于那些仅在系统启动过程中才会使用到的函数和数据,例如start_kernel(),仅在系统启动时使用,后面就废弃了。通过使用编译连接脚本将这类函数及数据分别划入到.init.text及.init.data段,并使用__init_begin和__init_end将其标识出来。然后在初始化的收尾阶段,通过free_kernel_image_pages()将其释放给系统内存,归入到buddy算法的管理当中。

面向用户态程序,内存分配提供了哪些接口?
brk:入参是指定堆的结束地址(绝对地址),其返回0表示成功,而返回-1表示失败,意味着没有内存空间了。
sbrk:入参指定扩展堆的大小(相对地址),而返回值为新设置的堆结束地址(绝对地址),用户态的malloc不会调用到该函数。
mmap:将一个文件或者其它对象映射进内存,即分配虚拟空间。文件可被映射到多个页上,如果占用的页面超过文件大小,末尾未使用空间清零( Linux堆空间未使用内存均清零)。
munmap:解除文件与内存之间的映射关系。
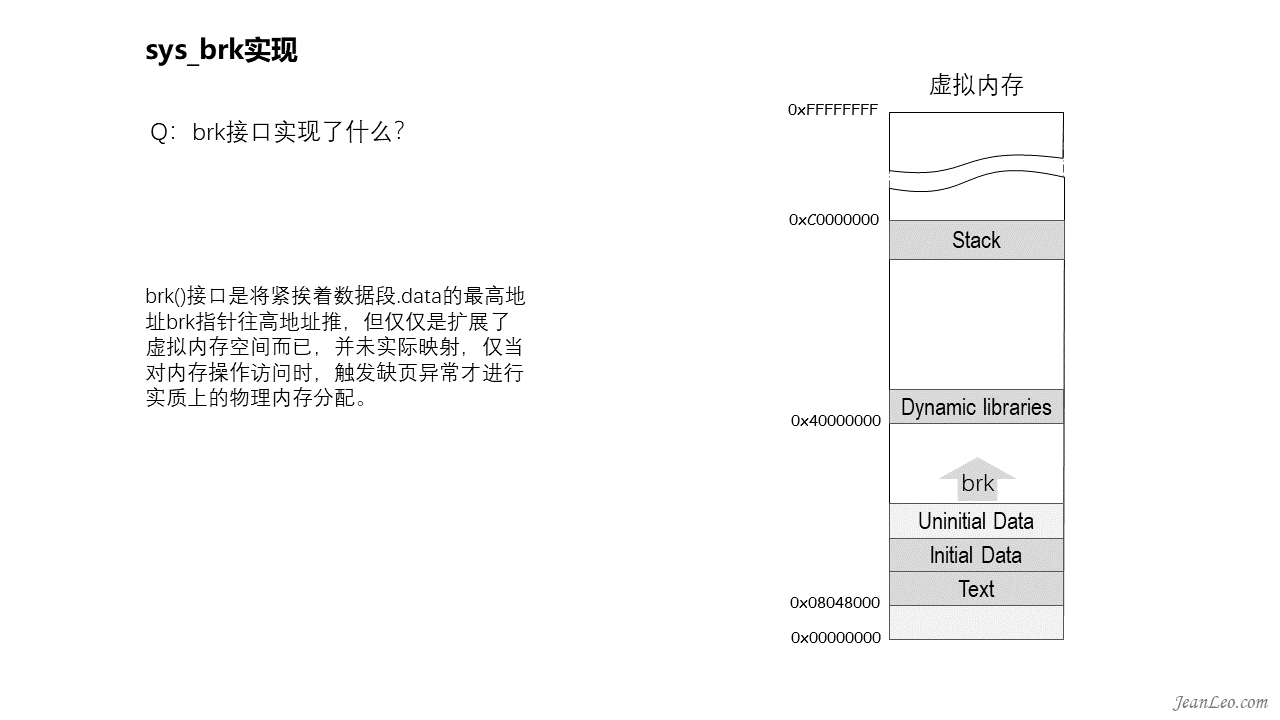
brk接口实现了什么?
brk()接口是将紧挨着数据段.data的最高地址brk指针往高地址推,但仅仅是扩展了虚拟内存空间而已,并未实际映射,仅当对内存操作访问时,触发缺页异常才进行实质上的物理内存分配。
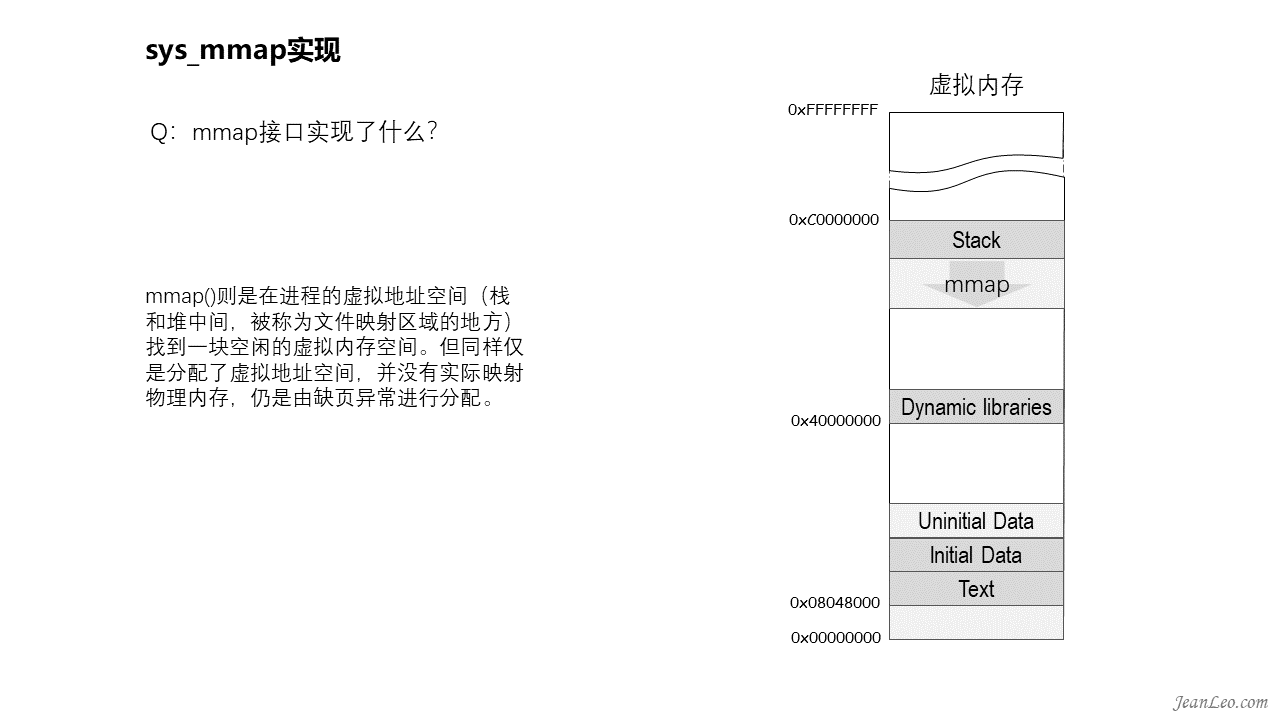
mmap接口实现了什么?
mmap()则是在进程的虚拟地址空间(栈和堆中间,被称为文件映射区域的地方)找到一块空闲的虚拟内存空间。但同样仅是分配了虚拟地址空间,并没有实际映射物理内存,仍是由缺页异常进行分配。
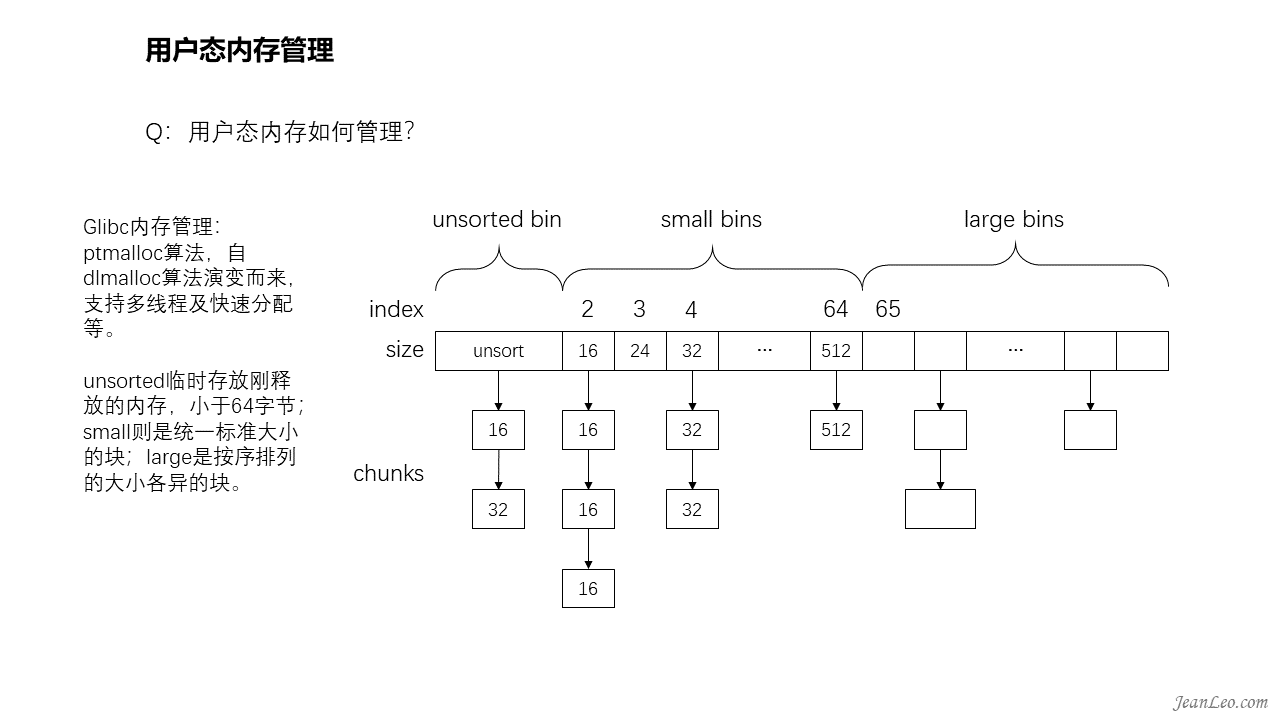
用户态内存如何管理?
Glibc内存管理采用的是ptmalloc算法,源自dlmalloc算法演变而来,支持多线程及快速分配等。unsorted临时存放刚释放的内存,小于64字节;small则是统一标准大小的块;large是按序排列的大小各异的块。

Glibc对brk和mmap的使用?
1.malloc接口对于小于M_MMAP_THRESHOLD设置大小的内存分配,是通过brk来完成的;
2.malloc申请内存大小触发的brk分配内存并非按照实际申请的内存大小来分配的,通常会分配得更大一些,而后每次的brk分配的空间会根据连续申请的情况调整,目的是减少系统调用次数,提高内存利用率;
3.如果malloc申请的内存超过M_MMAP_THRESHOLD设置大小,将会通过mmap从内存中分配。
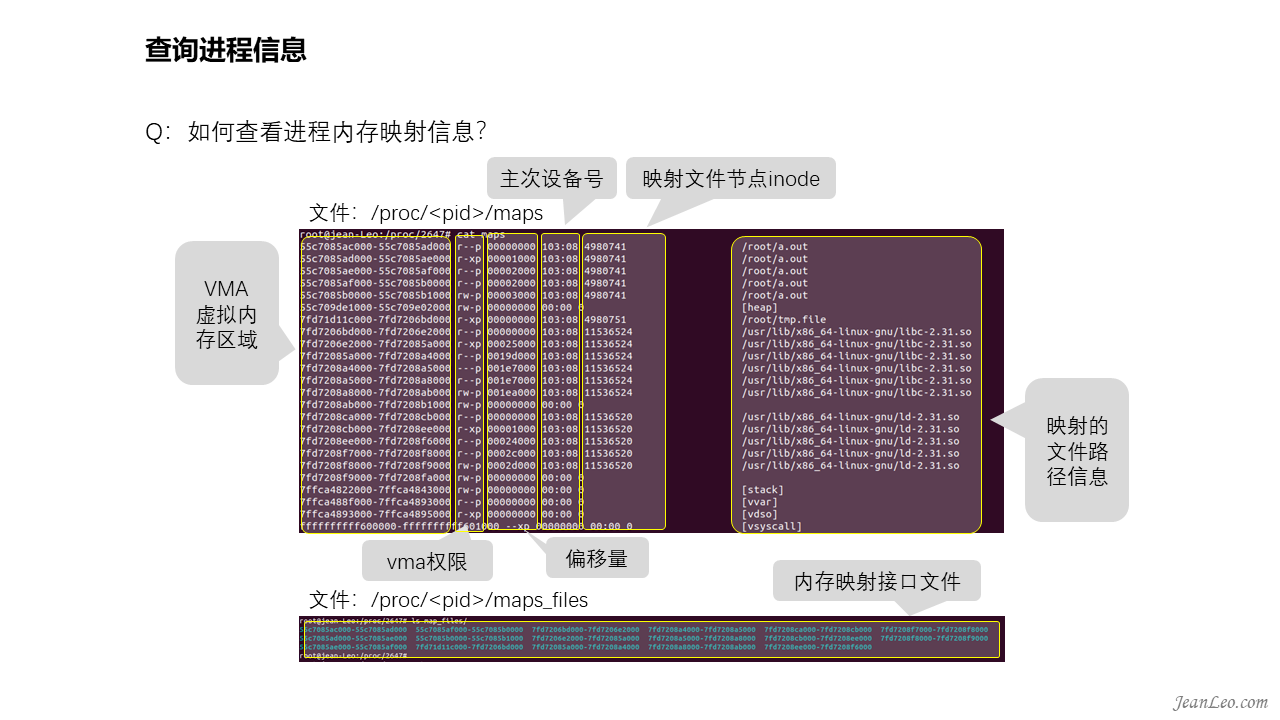
如何查看进程内存映射信息?
通过/proc/<pid>/maps可以查看到进程虚拟地址空间的映射以及对应权限,但是也仅是能看到虚拟地址空间而已,并不能够知道物理内存占用了多少,有多少内存页面是已经映射了的。而/proc/<pid>/maps_files目录下的文件则是对应于maps文件的映射,可以通过各个文件查看到各块虚拟内存的内容数据,不过有一点值得注意的是查看文件映射是可以全部都看到的,但是看到的也不是表示它已经映射了,这是接口读取文件的功劳。

如何查看进程内存占用实际情况?
对此,可以查看/proc/<pid>/numa_maps接口文件,该文件是基于maps的扩展,用于显示每个映射的内存的位置、绑定策略以及内存使用的页面数量。

如何查看进程内存片段映射详情?
Size:虚拟内存空间大小
Rss:已占用的物理内存,包括共享内存
Pss:剔除贡献内存后,Rss实际占用的物理内存
Shared_Clean/Shared_Dirty:Rss统计中共享的物理内存未被改写以及被改写的内存统计
Private_Clean/Private_Dirty:Pss统计未被改写以及被改写的内存统计
Referenced:被标记为已引用的页面,即页面不可被移出
Shared/Private_Hugetlb:由hugetlbfs页面支持的内存使用量
Swap:存在于交换分区的数据大小。
SwapRss:与Swap不同,不考虑基础shmem对象的swap出去的页面,即纯粹私有交换页面大小。
VmFlags:表示与特定虚拟内存区域关联的内核标志。
Locked:常驻物理内存的大小,这些内存页被锁定不会被换出。
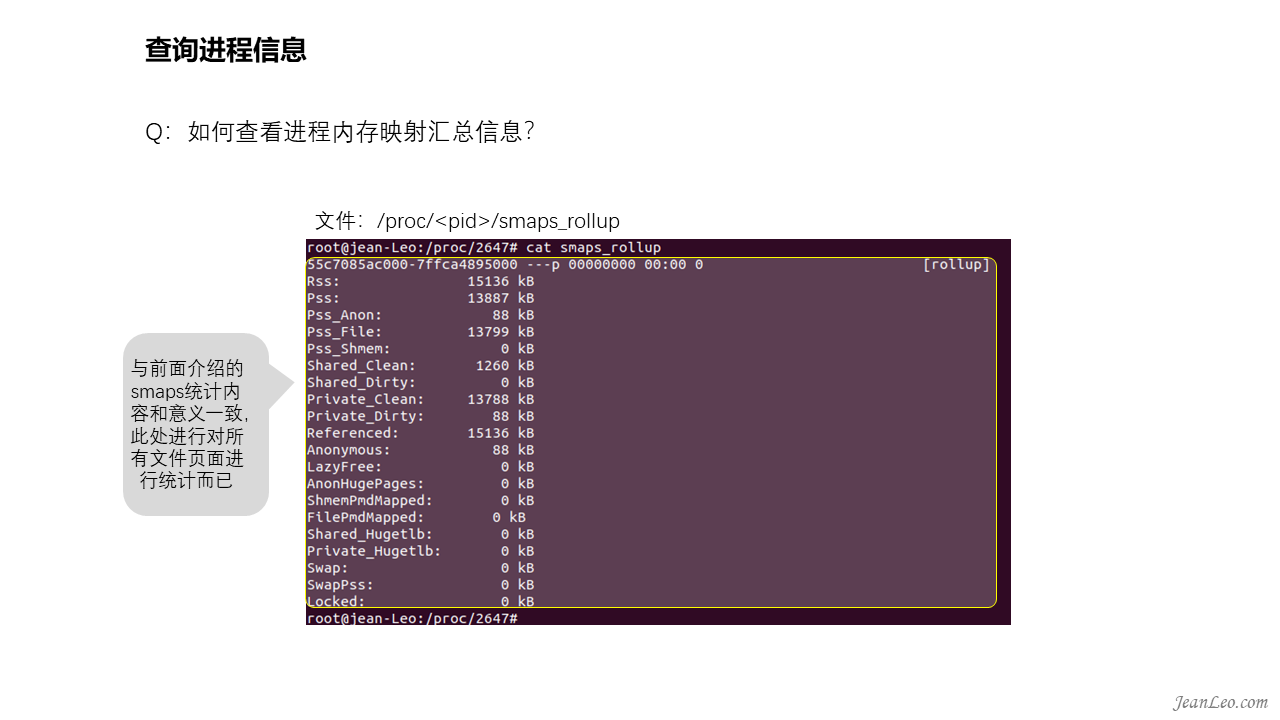
如图,可以通过/proc/<pid>/smaps_rollup查看进程内存映射汇总信息。
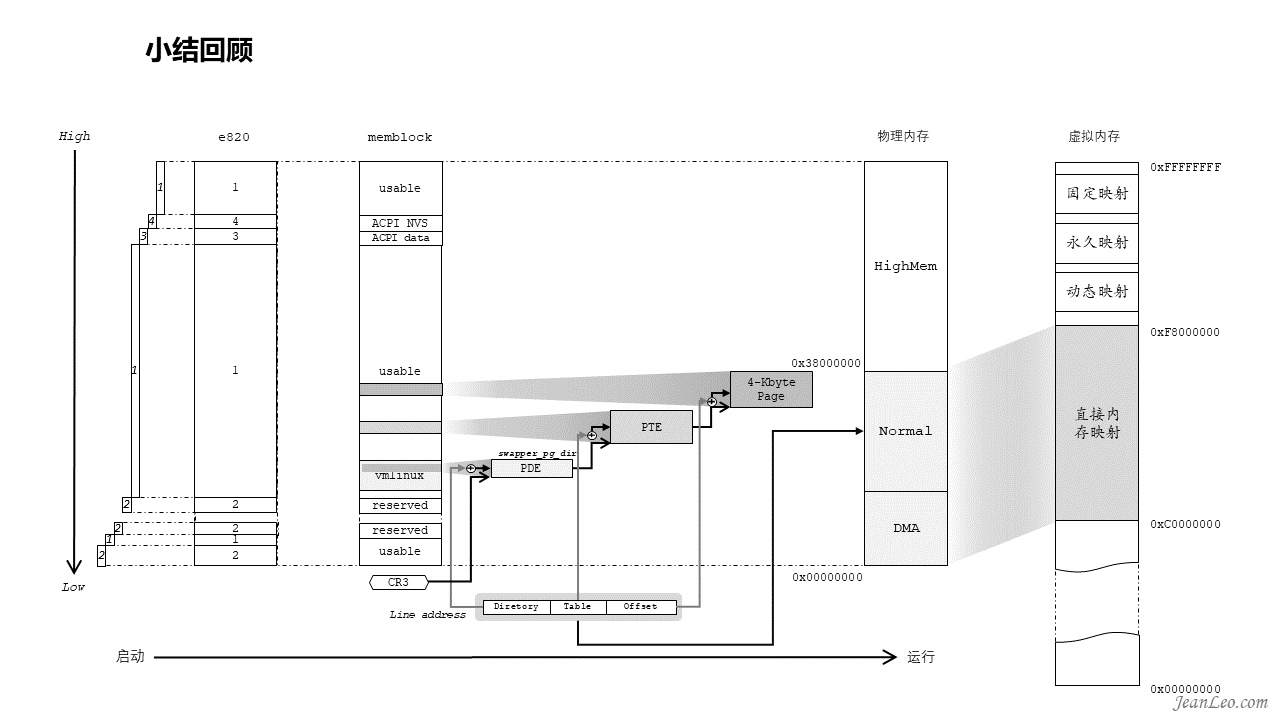
小结回顾,把整个初始化流程稍微串起来看一下。
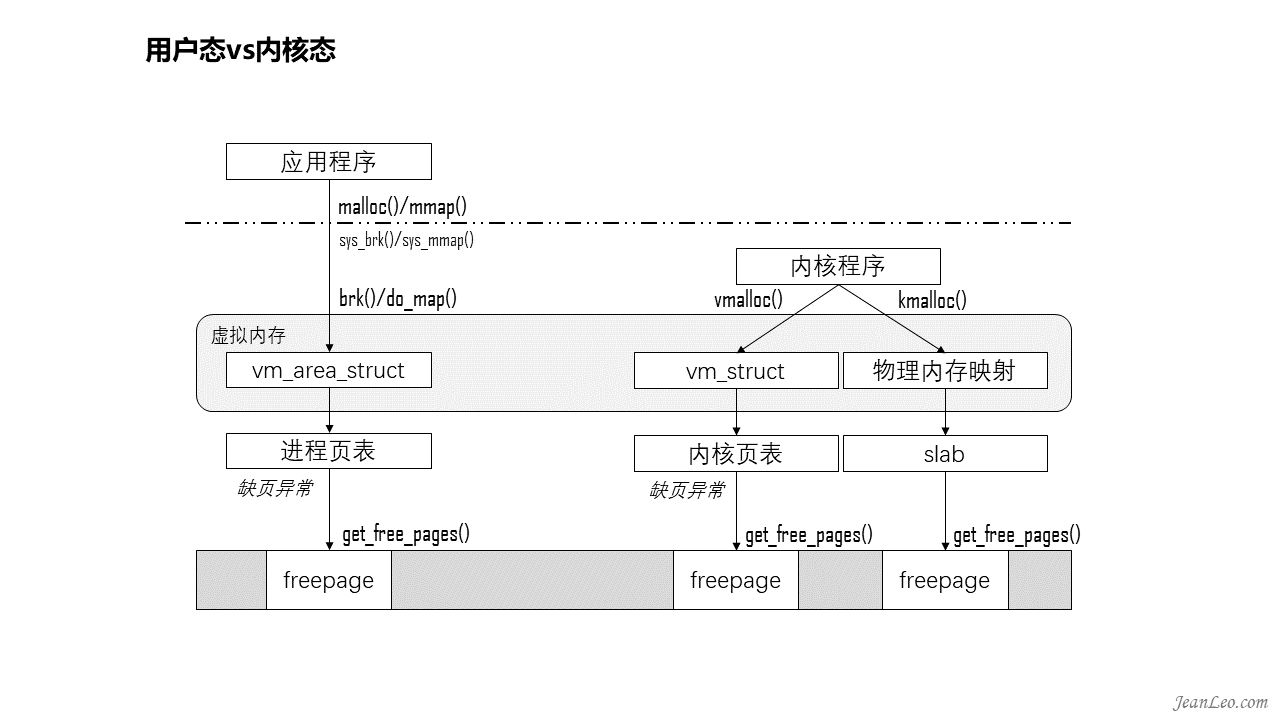
如图,内核态和用户态对内存操作的差异。

这初始化流程稍微串了一下,但是不尽人意,有个更详细的图,容我想想怎么展现。
就这样吧,拜拜!